
Your analytics dashboard can say traffic is healthy while AI answer engines quietly skip your best pages.
That is the uncomfortable part of AEO in 2026. A page can rank, convert, and still be hard for an LLM crawler to understand. The analysis engine becomes the layer that tells you whether your content is visible to answer systems, not just whether humans can read it.
Teams think the problem is more content. The real problem is whether answer engines can crawl, parse, verify, and reuse the content you already have.
That changes the conversation. This is not a definition exercise. It is an architecture problem: inputs, signals, scoring, workflows, ownership, and fixes that survive real production websites.
Table of contents
- Why an analysis engine matters for AEO in 2026
- What an analysis engine actually has to inspect
- Analysis engine inputs: the signals answer engines can use
- The workflow: from URL audit to action queue
- What breaks when teams treat AEO as content polish
- Schema, llms.txt, and crawler access are operating controls
- Designing an analysis engine score that teams can trust
- Implementation sequence for site owners and SEO teams
- What works, what fails, and how to review progress
- Where crawlproof.com fits into the analysis engine workflow
Why an analysis engine matters for AEO in 2026
Search ranking is no longer the only interface
For years, site teams optimized for a fairly visible path: search engine crawls page, search engine indexes page, user clicks blue link, analytics records session. That path still matters, but it is no longer the only top-of-funnel interface.
Answer engines, AI overviews, chat assistants, agentic browsers, and vertical research tools now compress the discovery process. A user may never visit the ten pages that informed the answer. The engine may summarize, compare, or cite a source directly inside the answer surface.
The practical question is not simply whether you rank. It is whether your page can be interpreted as a useful source when an answer system is trying to assemble a response.
That is where an analysis engine becomes operational. It does not replace SEO. It checks a different layer: what machines can access, extract, and trust when they evaluate your content.
If your team is still separating classic SEO from answer engine optimization, it helps to start with the basics in what AEO is and why it is not just SEO, then treat the analysis engine as the way you operationalize that difference.
The real system is crawl, parse, trust, cite
A useful way to think about it is a four-stage pipeline.
- Can the AI crawler access the page and supporting files?
- Can it parse the main content without losing meaning?
- Can it identify who is saying what, and why the source should be trusted?
- Can it cite or reuse the content in a way that maps to a user question?
Most AEO failures happen before the content quality conversation even starts. JavaScript hides important sections. Robots rules block the wrong agents. Schema says one thing while the page says another. Product pages answer buying questions visually but not textually. Author pages exist for humans but are not connected to article markup.
Practical rule: Treat AEO as a retrieval and interpretation workflow, not as a writing style guide.
The mistake teams make is assuming answer engines behave like patient readers. They do not. They behave like systems under constraints. They fetch, segment, classify, summarize, and choose sources. Your job is to make that process less ambiguous.
What an analysis engine actually has to inspect

Rendered page content is only the first layer
A browser screenshot is not enough. An analysis engine has to inspect what is returned over HTTP, what appears after rendering, and what is visible in the document structure.
For AEO, the important question is: what can an automated system confidently extract?
That includes the page title, headings, body copy, canonical URL, internal links, navigation, article metadata, product facts, organization information, and answer-like sections. It also includes what is missing. If the page claims to be a pricing guide but does not expose prices, ranges, caveats, or decision criteria in crawlable text, an answer engine has less to work with.
What breaks in practice is that many polished pages rely on design systems that fragment content. Cards, tabs, accordions, carousels, and client-side widgets can all be fine, but the analysis engine should verify whether the meaningful text survives extraction.
Machine-readable structure carries operational meaning
Schema markup is not decoration. It is a machine-readable claim about the page and the entity behind it. The analysis engine should check whether structured data exists, whether it is valid, and whether it matches visible content.
For example, an article page might expose Article schema but omit author identity, date modified, publisher, or canonical URL. A software page might describe itself as a generic WebPage instead of a SoftwareApplication or Product where appropriate. A local business might have address and service information visible to users but not represented in structured data.
The point is not to add every schema type possible. That usually creates noise. The point is to describe the business reality in a way answer systems can reconcile with the page.
Access rules decide whether the rest matters
Before content and schema matter, crawlers need access. An analysis engine should inspect robots.txt, meta robots, x-robots headers, CDN or WAF behavior, blocked assets, sitemap availability, canonical tags, and AI-specific access patterns.
This is where marketing and engineering often talk past each other. Marketing asks why content is not showing up. Engineering points to a standard robots policy. Legal asks whether AI crawlers should be blocked. Nobody owns the operational map.
The analysis engine should not decide policy for you. It should show the consequences of that policy.
| Layer | What good looks like | What fails in practice |
|---|---|---|
| Crawling | Important URLs are reachable by intended crawlers | AI bots blocked accidentally by broad rules |
| Rendering | Main content is present in extractable HTML or rendered output | Critical copy hidden behind client-side states |
| Structure | Schema matches visible page facts | Markup is generic, stale, or contradictory |
| Trust | Authors, organization, dates, and sources are clear | Content is anonymous or disconnected from entity pages |
| Actionability | Findings map to owners and fixes | Audit produces a score nobody can act on |
Related reading from our network: teams working on decentralized compute face similar architecture tradeoffs around visibility, routing, and workload ownership in cloud computing services for decentralized compute builders.
Analysis engine inputs: the signals answer engines can use
Content signals
Content signals are the parts of the page that help an answer engine understand what the page can answer. These include headings, question-and-answer patterns, definitions, comparisons, examples, tables, steps, caveats, and clear summaries.
But do not reduce this to FAQ stuffing. Answer engines do not only need short answers. They need context. A buying guide should explain tradeoffs. A technical page should define constraints. A service page should say who it is for, what the process looks like, what outcomes are realistic, and what boundaries apply.
The analysis engine should identify whether the page has extractable answers for the queries it appears to target. If the page targets analysis engine, for example, it should not only define the phrase. It should show inputs, outputs, scoring logic, failure modes, and implementation workflow.
Technical signals
Technical signals determine whether content survives the path from URL to usable source. The analysis engine should check status codes, redirects, canonicalization, hreflang where relevant, sitemap inclusion, robots directives, page speed constraints that affect rendering, and blocked resources.
For AI crawlers and answer engines, you should also inspect whether key files exist and are accessible. That includes robots.txt, sitemap.xml, structured data, and emerging guidance files. If you are evaluating llms.txt or skill.md, the practical question is not whether the file is trendy. It is whether it gives crawlers a concise map to canonical, high-value resources. The mechanics are covered in more detail in llms.txt and skill.md explained.
Trust and positioning signals
Answer systems need to decide whether a source is useful enough to cite. They may use many signals, and none of us should pretend to know every proprietary ranking feature. But site owners can control the basics.
Make the organization clear. Connect authors to expertise. Keep dates accurate. Cite primary sources when appropriate. Explain methodology for claims. Maintain consistent entity information across key pages.
Practical rule: If a human reviewer cannot quickly tell who owns the content and why it should be trusted, do not expect an answer engine to infer it perfectly.
This is not about adding performative trust badges. It is about reducing ambiguity. A vague page is easy to ignore. A clear page with extractable claims, provenance, and structure is easier to reuse.
The workflow: from URL audit to action queue

Step 1: fetch like a crawler, not like a browser
The first job of an AEO analysis engine is to fetch the page in ways that reveal crawler reality. A normal browser session can hide too much. You want to compare raw HTML, rendered HTML, headers, directives, and resources.
A basic workflow looks like this:
- Submit a canonical URL, not a campaign URL.
- Fetch the page with a standard user agent and with AI-crawler-like user agents where appropriate.
- Record status code, redirects, canonical tag, robots directives, and response headers.
- Extract visible text, headings, links, schema, and metadata.
- Compare extracted content against what a human sees on the page.
- Flag differences that affect answer usefulness.
This is where many audits become useful immediately. If the analysis engine shows that the main answer section does not appear in the extracted text, the fix may be technical rather than editorial.
Step 2: extract entities, claims, and answers
After fetching, the analysis engine should parse the page into units that matter for answer generation. Entities are people, products, companies, places, frameworks, and concepts. Claims are assertions the page makes. Answers are passages that respond to common user questions.
For a software page, the extraction might include product category, use cases, integrations, pricing model, support boundaries, data handling, and comparison points. For a blog article, it might include thesis, definitions, steps, examples, and caveats.
The mistake teams make is auditing pages only for keywords. Keywords still matter, but answer engines need reusable passages. If the page contains the target phrase twenty times but never states a clear answer, it is not citation-ready.
Step 3: turn findings into owned work
An analysis engine that ends with a grade is only half-built. The output should become an action queue.
A useful finding has five parts:
- The affected URL.
- The failed signal.
- The evidence observed by the crawler.
- The likely impact on AEO.
- The owner who can fix it.
For example, blocked AI crawler access may belong to engineering and legal. Missing author markup may belong to content operations. Contradictory schema may belong to SEO and development. Thin answer sections may belong to editorial.
Related reading from our network: streaming teams see the same handoff problem when architecture spans ingest, transcoding, caching, and observability; the breakdown is useful in cloud computing IPTV architecture.
What breaks when teams treat AEO as content polish
The page looks good but extracts badly
This is the most common failure mode. The page is attractive, well-written, and usable by a human. But the extracted text is missing the important parts, or the structure makes the page look like a pile of unrelated snippets.
Common causes include:
- Important content loaded only after interaction.
- Comparison data stored in images without text alternatives.
- Product facts split across decorative cards.
- Headings chosen for design rather than hierarchy.
- Multiple pages canonicalized to the wrong URL.
- Boilerplate overwhelming the main content.
The analysis engine should make these failures visible. Not as abstract best practices, but as evidence: here is what the crawler saw, here is what it missed, and here is why that matters.
The audit finds issues nobody owns
AEO touches content, SEO, engineering, product, brand, legal, and analytics. That is why generic audits stall. They identify problems but do not route them.
The practical fix is to classify findings by owner from the beginning.
- Access and rendering issues go to engineering.
- Schema and metadata issues go to SEO or web operations.
- Thin answer coverage goes to content.
- Trust and entity gaps go to brand, editorial, or leadership.
- Policy choices around AI crawlers go to legal and business owners.
Practical rule: Every AEO finding should have an owner, a severity, and a next action. Otherwise it is commentary, not operations.
The score improves while citation readiness does not
Scores are useful only if they measure the right thing. A team can improve a superficial score by adding schema, expanding copy, and creating FAQ blocks without making the page more useful to answer engines.
Citation readiness is harder. It asks whether the page contains clear, sourceable, current, entity-connected information that answers real questions better than alternatives.
That is why the analysis engine should separate blockers from enhancements. A missing canonical tag can be a blocker. Weak examples may be an enhancement. Generic schema may be a medium issue. The score should reflect operational severity, not a checklist count.
Schema, llms.txt, and crawler access are operating controls
Schema should describe the business reality
Schema works best when it reflects what is already true on the page. If the page is an article, mark it up as an article with accurate author, publisher, date, and headline information. If it is a product or software page, expose the relevant product facts that users can also verify visually.
Bad schema creates a reconciliation problem. If the markup says one thing and the content says another, a machine has to decide which to trust. Often the safest answer is to trust neither strongly.
The analysis engine should flag schema problems in plain language:
- Missing recommended properties.
- Invalid JSON-LD.
- Multiple conflicting entity definitions.
- Markup that does not match visible content.
- Organization data disconnected from the page entity.
llms.txt is a navigation hint, not a magic switch
The hype around llms.txt can make it sound like a ranking lever. A more grounded view is that it is a navigation hint. It can point AI systems to the pages you consider canonical, useful, and safe to summarize.
That matters because many websites have too many URLs: tag pages, duplicate posts, parameterized pages, stale docs, print views, and archived campaigns. A concise llms.txt file can help express editorial intent.
But it cannot fix blocked pages, weak content, contradictory schema, or unclear ownership. The analysis engine should inspect the file, validate that linked URLs are reachable, and compare the file against sitemap and internal linking priorities.
Robots rules create policy, not strategy
Robots rules are often treated as a one-time technical setting. In AEO, they are business policy. You are deciding which automated systems can access which parts of your site.
There are valid reasons to block some crawlers or paths. There are also accidental blocks that quietly remove important pages from AI discovery. The analysis engine should surface both.
A practical crawler-access review should ask:
- Which AI crawlers are allowed?
- Which directories are blocked?
- Are important assets blocked?
- Do meta robots tags contradict robots.txt intent?
- Are CDN or WAF rules treating AI crawlers differently?
- Are policy decisions documented?
Related reading from our network: checkout teams face a similar difference between surface UI and operational rules; this workflow view of Shutterfly promo codes in 2026 is a useful adjacent example of why the visible screen is not the whole system.
Designing an analysis engine score that teams can trust
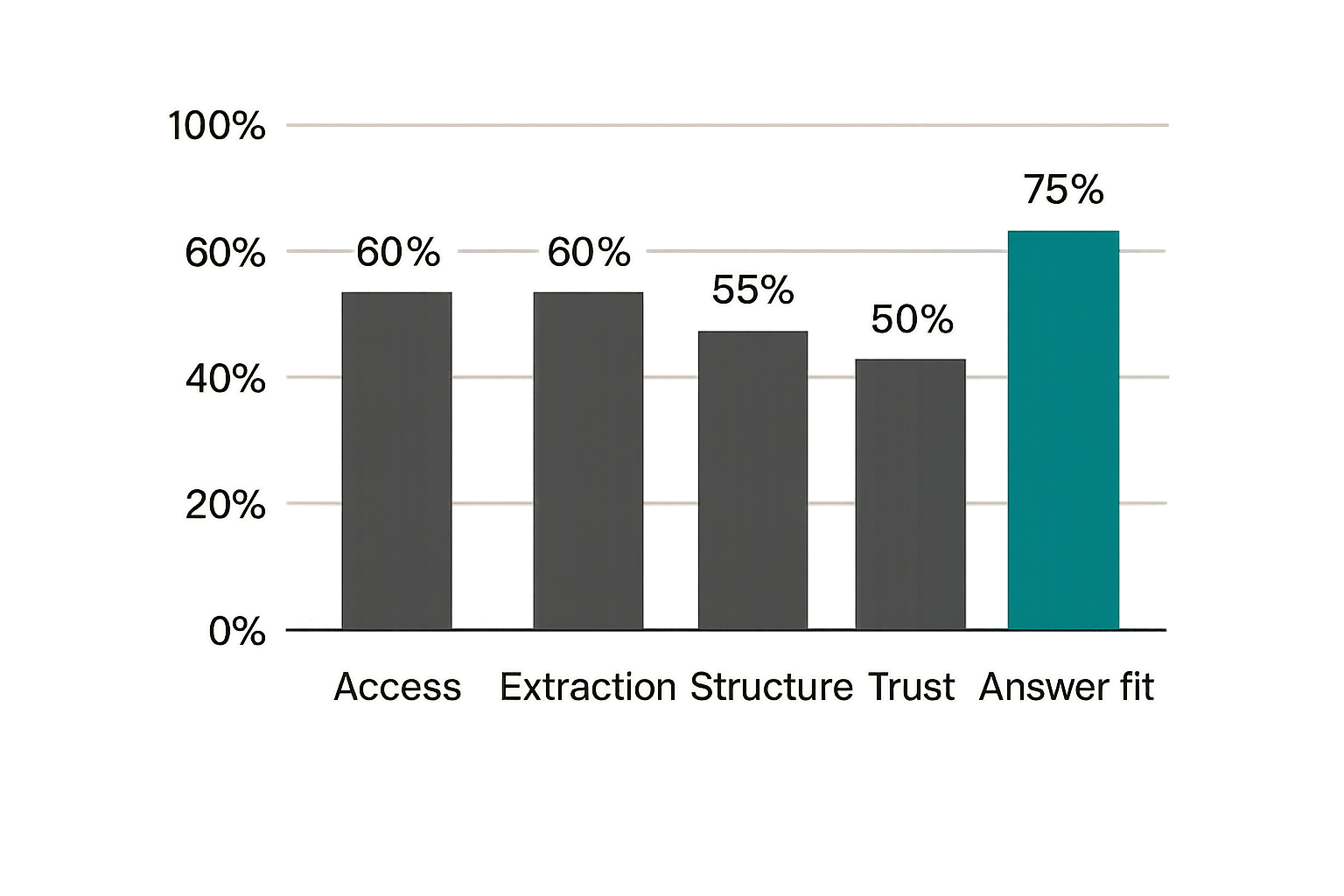
Separate visibility from usefulness
A trustworthy analysis engine score should not collapse everything into one vague number. Visibility and usefulness are different.
Visibility asks whether the page can be found and processed. Usefulness asks whether the extracted content helps answer a question.
A page can be visible but not useful. It may crawl cleanly while saying very little. A page can also be useful but not visible. It may contain excellent guidance behind blocked rendering or confusing directives.
A better score model separates categories:
| Category | Example checks | Why it matters |
|---|---|---|
| Access | Status, redirects, robots, headers | Determines whether crawlers can reach the page |
| Extraction | Main content, headings, links, rendered text | Determines whether meaning survives parsing |
| Structure | Schema, canonical, sitemap, metadata | Helps machines classify the page correctly |
| Trust | Author, publisher, dates, entity clarity | Supports source confidence |
| Answer fit | Questions answered, examples, caveats | Determines whether the page is useful in responses |
Weight blockers harder than enhancements
Not every issue deserves equal weight. A missing alt attribute on a decorative image is not the same as a noindex tag on a revenue page. A stale date may matter more on a medical or legal article than on an evergreen glossary page.
The analysis engine should support severity tiers.
- Critical: prevents crawling, indexing, extraction, or trust in a major way.
- High: weakens interpretation on important pages.
- Medium: reduces clarity or completeness.
- Low: improves quality but is unlikely to block reuse.
This is how you prevent audit fatigue. Teams can work the queue in the right order instead of arguing about a long list of equal-looking recommendations.
Show evidence, not just grades
A grade without evidence creates debate. Evidence creates work.
For each finding, show the observed data. If schema is missing, show the detected schema types. If content extraction is weak, show the extracted main text. If robots rules block a crawler, show the matching rule. If the page lacks answer-ready sections, show which query intents appear unsupported.
Practical rule: The more automated the score, the more visible the evidence needs to be.
This matters for trust inside your team. Developers do not want vague SEO tickets. Content teams do not want mysterious technical scores. Executives do not want a dashboard that cannot explain its own recommendations.
Implementation sequence for site owners and SEO teams
Start with revenue pages and canonical explainers
Do not start by auditing every URL. Start with the pages that matter most.
For most sites, that means:
- Home page.
- Main product or service pages.
- Pricing or comparison pages.
- Core category pages.
- Canonical educational articles.
- Documentation or support pages that answer buying objections.
This gives you a representative map. You will see whether failures are isolated or systemic. If every template has the same extraction problem, fix the template before rewriting individual pages.
Add AEO checks to publishing and deploy workflows
AEO audits should not happen only after traffic drops. Add them to the workflows where pages change.
For content teams, that means checking answer coverage, headings, summaries, author information, internal links, and freshness before publication. For developers, it means checking schema validity, rendering, canonical tags, robots directives, and blocked resources before deployment.
A simple implementation sequence:
- Define the URL classes that need AEO checks.
- Create baseline audits for representative pages.
- Fix template-level blockers first.
- Add page-level editorial improvements.
- Re-run audits after deploys.
- Review crawler access policy quarterly.
- Track whether important pages become more extractable and more citation-ready.
Review crawler behavior on a schedule
AI crawler behavior changes. Your site changes too. New sections launch. CMS templates get replaced. Security rules get tightened. Legal policy evolves. A one-time analysis engine audit decays quickly.
Set a review schedule based on risk. High-value pages deserve more frequent checks. Large sites should sample by template and section. Smaller sites can audit the core set monthly or after major updates.
The key is to make AEO observable. If answer engines are becoming a discovery layer, then crawler access, extraction quality, and structured data cannot be invisible infrastructure.
What works, what fails, and how to review progress
What works
What works is boring in the best way: clear pages, consistent structure, accessible content, accurate schema, documented crawler policy, and a queue that assigns work to the right people.
Strong AEO programs usually have these habits:
- They audit pages from the crawler perspective.
- They prioritize pages by business value.
- They separate technical blockers from content improvements.
- They keep schema aligned with visible content.
- They maintain entity clarity across the site.
- They treat llms.txt and sitemaps as maps, not magic.
- They review changes after deploys.
A useful analysis engine reinforces these habits. It keeps the conversation grounded in what the machine can actually find.
What fails
What fails is treating AEO like a campaign. A few FAQ blocks, a generic schema plugin, a new glossary, and a dashboard number will not build durable visibility.
Common failure patterns include:
- Auditing only the homepage.
- Ignoring templates and CMS constraints.
- Allowing robots policy to drift without review.
- Publishing content that answers around the question but never answers it directly.
- Adding schema without validating it.
- Measuring only traffic, not machine accessibility.
- Sending every issue to the SEO team regardless of cause.
The mistake teams make is looking for a single lever. The real system is multi-layered. You need content, structure, access, and ownership working together.
Progress metrics worth watching
Do not invent fake certainty around AI citations. Many answer surfaces are opaque, volatile, and personalized. But you can still measure progress inside your own system.
Track metrics like:
- Percentage of priority URLs crawlable by intended agents.
- Percentage of priority URLs with valid, relevant schema.
- Number of critical extraction blockers by template.
- Number of pages with clear author, publisher, and date signals.
- Number of canonical pages included in llms.txt or equivalent guidance.
- Reduction in unresolved AEO findings over time.
- Manual spot checks of whether answer-ready passages exist.
These are not vanity metrics. They tell you whether your site is becoming easier for answer engines to use.
Where crawlproof.com fits into the analysis engine workflow
Use it as an outside-in audit layer
CrawlProof is built for site owners and marketers who want to see their pages the way AI crawlers and answer engines see them. That makes it useful as an outside-in analysis engine layer, especially when your internal tools focus on traditional SEO, performance, or analytics.
The point is not to replace your CMS, analytics, or SEO platform. The point is to inspect the AEO path: content availability, schema, robots rules, AI-bot access, and positioning signals from the perspective of machine discovery.
You can run an audit on CrawlProof to see what AI crawlers can actually find and use the results to start a more precise conversation with content, SEO, and development teams.
Connect findings to the people who can fix them
The value of an analysis engine is not the scan. It is the workflow after the scan.
A good CrawlProof review should end with decisions:
- Which issues block AI crawler access?
- Which pages are important enough to fix first?
- Which findings are template-level defects?
- Which findings require editorial improvement?
- Which crawler policies need business approval?
- Which changes should be re-tested after deployment?
That is the operational layer most teams are missing. They have content calendars, SEO dashboards, and developer backlogs. They do not yet have a clean workflow for answer engine readiness.
Try crawlproof.com
crawlproof.com helps site owners and marketers understand how AI answer engines and LLM crawlers discover and cite their content. Use it as the practical analysis engine for AEO audits, crawler access checks, schema review, and citation readiness.