
Most site owners are now running AEO experiments with bad feedback loops. They rewrite pages, add schema, publish comparison content, adjust robots rules, and wait to see whether ChatGPT, Perplexity, Gemini, Claude, or AI Overviews cite them more often.
Then the report comes back noisy. One prompt shows the brand. Another does not. One crawler hits the page. Another ignores it. A competitor gets cited for a query where your page is technically better.
Teams think the problem is Bayesian optimization as a math concept. The real problem is that AEO work has become an experimentation system with expensive, delayed, incomplete feedback.
That changes the conversation. Bayesian optimization is useful for answer engine optimization because it gives teams a disciplined way to choose the next best test when they cannot afford to test everything. The practical question is not “can we use machine learning for SEO?” It is “how do we decide what to change next when AI visibility signals are sparse, probabilistic, and hard to attribute?”
Table of contents
- Bayesian optimization is an experimentation architecture
- Where Bayesian optimization fits in AEO
- Define the objective before you optimize
- Choose variables that answer engines can actually see
- Build the Bayesian optimization workflow
- What works and what fails
- Use Bayesian optimization for content strategy
- Use Bayesian optimization for technical AEO
- Common failure modes in Bayesian AEO programs
- How CrawlProof fits into the workflow
Bayesian optimization is an experimentation architecture

The mistake teams make is treating Bayesian optimization as a black-box algorithm that magically finds traffic. In practice, it is closer to an operating system for choosing tests.
A useful way to think about it is this: you have a landscape of possible website changes. Some changes improve AI answer visibility. Some do nothing. Some make the site clearer for human readers but less extractable for crawlers. You cannot test every combination because each test has cost, latency, and risk.
Bayesian optimization helps you decide where to sample next. It balances exploitation, which means doing more of what appears to work, with exploration, which means testing uncertain changes that may have higher upside.
Why AEO experiments are expensive
AEO experiments are not expensive because changing a heading is hard. They are expensive because the feedback loop is messy.
You may need to wait for multiple crawlers to revisit the page. You may need to test prompt variants. You may need to separate changes caused by your edits from changes caused by model updates, competitor updates, or answer engine UI changes.
Costs usually show up as:
- editorial time to rewrite and restructure content;
- developer time to adjust templates, schema, redirects, or rendering;
- QA time to verify what bots can fetch and parse;
- opportunity cost from choosing one page or topic over another;
- brand risk if an answer engine extracts the wrong claim.
Practical rule: use Bayesian optimization only when tests are costly enough that choosing the next test matters.
If you can test all options quickly, do that. If you have hundreds of pages, multiple answer engines, and uncertain signals, you need prioritization.
Why simple A/B testing breaks
Classic A/B testing assumes you can split traffic, isolate variants, and measure conversions with clean instrumentation. AEO rarely works that way.
You cannot reliably split ChatGPT traffic into variant A and variant B. You cannot force an AI answer engine to crawl both versions on schedule. You cannot assume that a citation is caused by the last visible change you made.
What breaks in practice is attribution. A page may be cited because of its content, schema, internal links, page authority, freshness, or a third-party source summarizing it. Simple A/B logic becomes too brittle.
Bayesian optimization does not solve all attribution problems. It gives you a better way to act under uncertainty.
The operator version of Bayesian optimization
You do not need to start with Gaussian processes, acquisition functions, or custom notebooks. The operator version is simpler:
- Define what improvement means.
- List the changes you can make.
- Estimate which changes are likely to help.
- Run a small batch of tests.
- Measure the outcome with consistent rules.
- Update your belief.
- Pick the next batch based on upside and uncertainty.
That is Bayesian optimization in a workflow form. The math can get more sophisticated later. The discipline matters first.
Related reading from our network: teams building software feedback loops face a similar issue in product iteration best practices, where the hard part is not shipping changes but deciding which signal deserves the next cycle.
Where Bayesian optimization fits in AEO
Bayesian optimization fits best when you have a portfolio of possible AEO moves and no obvious winner. This is common in 2026 because answer engines are evaluating pages through multiple surfaces: rendered HTML, schema, snippets, links, citations, entity relationships, and sometimes dedicated AI-facing files.
If you are still defining the basics of answer engine optimization, start with the distinction between search rankings and answer inclusion in what AEO is and why it is not just SEO. Bayesian optimization becomes useful after you understand that the answer engine is not only ranking pages. It is selecting, compressing, and citing evidence.
The decision you are optimizing
The first design choice is the decision unit. Are you optimizing:
- one page;
- one template;
- one topic cluster;
- one product category;
- one schema type;
- one crawler access policy;
- one prompt/query family?
Do not optimize everything at once. If your unit is too broad, the feedback becomes meaningless. If your unit is too narrow, you will never collect enough signal.
For most sites, the best unit is a page-template-query-cluster combination. Example: “SaaS comparison template pages for pricing-related AI prompts.” That is specific enough to change and broad enough to measure.
The signals you can observe
You cannot see the internal ranking model of an answer engine. You can observe surface signals:
- whether known AI crawlers request the page;
- whether the page is accessible to those crawlers;
- whether structured data is present and valid;
- whether the page contains extractable answer blocks;
- whether answer engines mention the brand;
- whether they cite the URL;
- whether cited claims match your intended positioning;
- whether referral traffic or assisted conversions move after visibility changes.
None of these is perfect. Together, they are useful.
Practical rule: do not optimize for a signal you cannot measure the same way twice.
If your team changes the prompt set every week, you are not learning. You are creating noise.
The constraints you cannot ignore
Bayesian optimization is only helpful if it respects real constraints. AEO teams usually operate under constraints like:
- limited writer and developer capacity;
- legal review for claims;
- fixed CMS templates;
- brand voice rules;
- schema support limitations;
- crawl budget and bot access policies;
- seasonality in demand;
- product pages that cannot be rewritten freely.
The model should not recommend actions the team cannot execute. If adding detailed FAQ schema is blocked by your CMS, it is not a candidate variable until the platform supports it.
Define the objective before you optimize
Bayesian optimization fails when the objective is vague. “Improve AI visibility” sounds reasonable, but it is not operational. You need a scoring system that turns messy observations into a consistent result.
The practical question is: what outcome would make the next experiment a success?
Citation visibility is not one metric
AI visibility has several layers:
- discovery: crawlers can access the page;
- extraction: crawlers can parse the important content;
- understanding: answer engines associate the page with the right entity and topic;
- selection: the system chooses your page as evidence;
- citation: the interface shows your URL or brand;
- accuracy: the generated answer reflects your claims correctly;
- commercial value: the mention influences demand, trust, or conversion.
A page can be discovered but not cited. It can be cited but misrepresented. It can be mentioned without a link. It can drive brand lift without trackable referral traffic.
This is why a single binary metric is too thin.
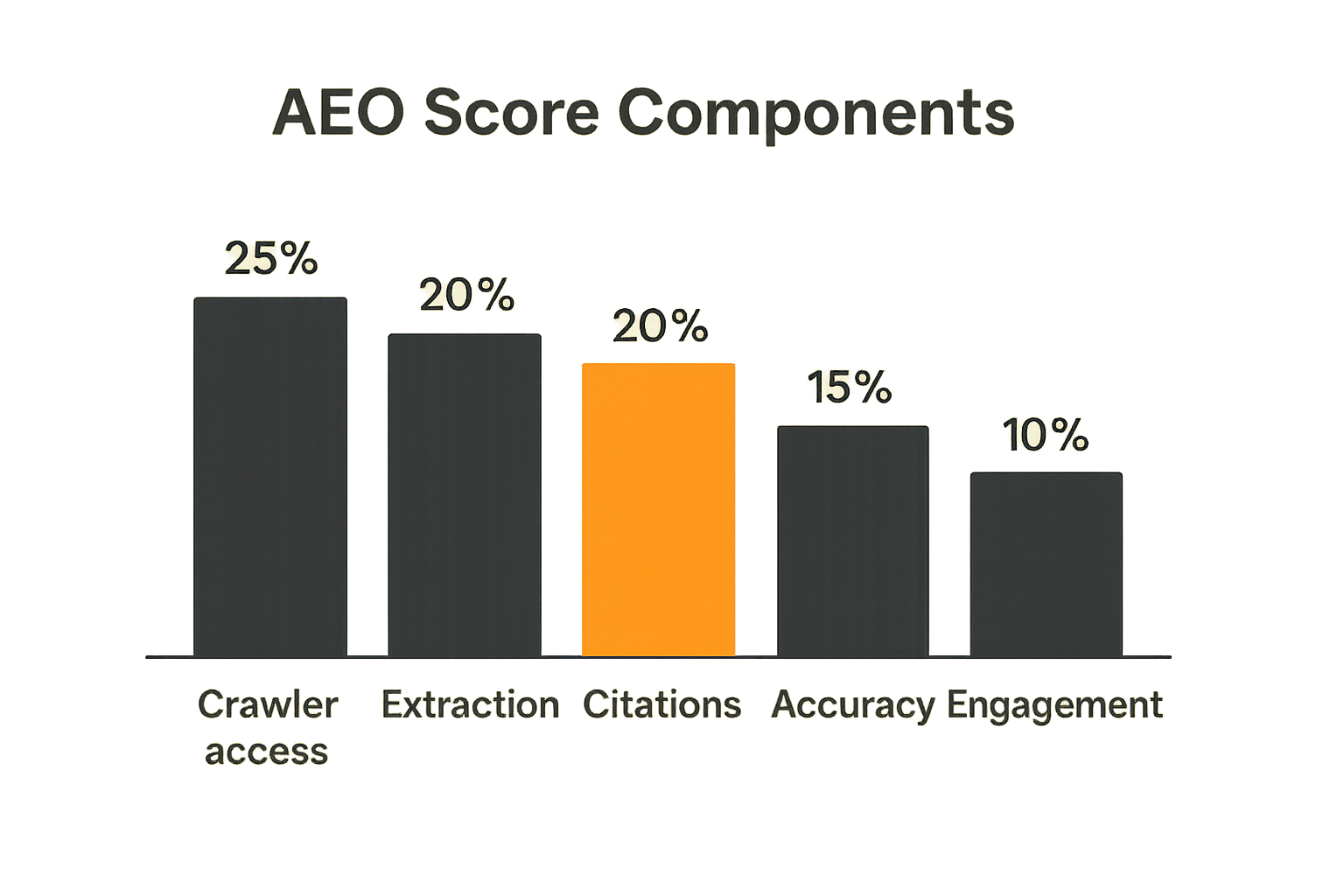
Build a scoring model you can defend
A practical AEO objective might use a weighted score:
AEO Score =
25% crawler accessibility
+ 20% structured extraction quality
+ 20% citation frequency across prompt set
+ 15% answer accuracy
+ 10% brand/entity consistency
+ 10% downstream engagement
The weights are not universal. A media site may weight citations heavily. A B2B software site may care more about accurate category positioning. A local business may care about inclusion in recommendation-style answers.
The key is consistency. If the scoring model changes every experiment, the optimizer is chasing a moving target.
Separate leading signals from business outcomes
Do not confuse leading AEO signals with revenue. They are connected, but not identical.
Leading signals include crawler access, schema validity, extractability, and prompt-level citation. Business outcomes include demo requests, assisted pipeline, affiliate clicks, subscriptions, or direct inquiries.
Bayesian optimization should usually optimize for a leading signal first, then validate whether that signal correlates with commercial value. Otherwise you wait too long and learn too little.
Practical rule: optimize fast signals, but audit slow business outcomes before scaling the tactic.
Choose variables that answer engines can actually see
The second major failure mode is optimizing variables that answer engines barely observe. If the system cannot crawl it, parse it, or associate it with the query, it is a weak experiment input.
AEO variables should be visible in the HTML, structured data, internal graph, public reputation layer, or AI-facing access rules.
Content variables
Content variables are the easiest to understand and the easiest to overuse. They include:
- page title and H1 framing;
- answer-first summaries;
- comparison tables;
- definitions and entity descriptions;
- concise claims with supporting context;
- product use cases;
- FAQ sections;
- original examples;
- author and organization details;
- freshness signals.
The mistake teams make is rewriting entire pages and then claiming the test proved “better content works.” That is not a test. That is a bundle of changes.
Better variables are smaller:
- add a 90-word answer block near the top;
- add a comparison table for the target decision;
- rewrite the first 250 words to state the category clearly;
- add three entity-specific examples;
- replace generic FAQs with prompt-shaped questions.
Technical discovery variables
Technical variables decide whether crawlers can fetch and understand the page. These include:
- robots.txt access for AI crawlers;
- server responses by user agent;
- JavaScript rendering requirements;
- canonical tags;
- sitemap inclusion;
- internal link depth;
- schema markup;
- page speed and server reliability;
- llms.txt or related AI-facing files.
If you are testing AI-facing discovery files, make sure the file is coherent and useful. A shallow file that lists random URLs is not strategy. For practical context on these files, see the CrawlProof guide to llms.txt and skill.md.
Authority and positioning variables
Answer engines do not only look at your page. They also infer whether your site is a credible source for a topic.
Authority variables are harder to test but important:
- author credentials;
- organization schema;
- external references;
- mentions from trusted sources;
- consistent entity naming;
- topical depth across the site;
- internal links from relevant pages;
- clear product and category positioning.
These variables have slower feedback loops. Bayesian optimization can still help, but you should avoid mixing them with quick copy edits in the same experiment batch.
Related reading from our network: local networks face a similar naming and trust problem, where a “community” label becomes routing architecture rather than wording; see this piece on community synonym choices as local network architecture.
Build the Bayesian optimization workflow
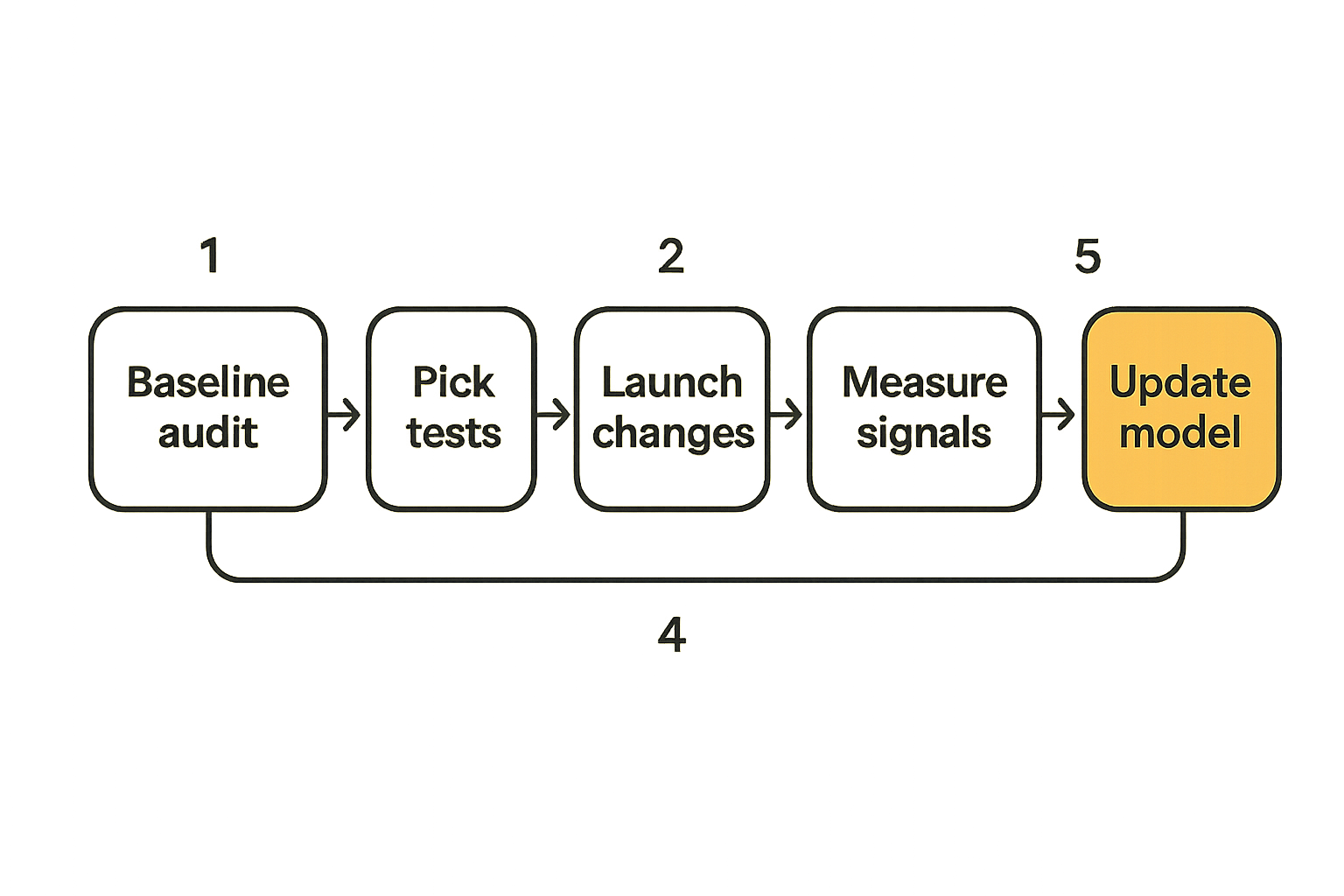
A usable Bayesian optimization workflow for AEO does not need to be fancy. It needs to be repeatable. The point is to stop making random changes and start maintaining an experiment memory.
Step 1 create the experiment ledger
Start with a ledger. A spreadsheet is fine until it is not. Each row should represent one experiment candidate or completed test.
Minimum fields:
- experiment ID;
- page or template;
- query cluster;
- hypothesis;
- variable changed;
- baseline score;
- expected upside;
- uncertainty level;
- cost to implement;
- risk level;
- launch date;
- crawl observation date;
- measurement date;
- result score;
- notes and confounders.
A simple hypothesis should read like this:
If we add an answer-first comparison block to our product alternatives page,
then AI answer engines will be more likely to cite the page for
"best alternatives to [category leader]" prompts,
because the page will provide extractable, decision-ready evidence.
That is measurable. “Make page better for AI” is not.
Step 2 pick the first test set
Your first batch should not be purely obvious winners. It should include a mix:
- high-confidence, low-cost changes;
- high-upside, uncertain changes;
- technical fixes that remove measurement blockers;
- one or two negative controls where you expect little movement.
This prevents your program from becoming confirmation bias with a dashboard.
A practical first sequence:
- Choose 20 important pages or templates.
- Group them into 4 to 6 query clusters.
- Run a baseline AEO audit for access, extractability, schema, and prompt visibility.
- Score each page with the same rubric.
- Select 5 experiments with different variable types.
- Launch changes in a documented order.
- Wait through a defined crawl and measurement window.
- Re-score using the same prompt set and audit checks.
- Update the ledger with result, cost, and confidence.
- Choose the next batch based on expected improvement and uncertainty.
Practical rule: the first goal is not to maximize citations. The first goal is to build a reliable learning loop.
Step 3 update the model and choose the next move
In a lightweight version, you can score each candidate with a formula:
Priority Score =
(Expected Upside x Confidence Adjustment x Strategic Value)
/ (Implementation Cost x Risk)
Then adjust confidence after each test. If answer blocks improve citation rates for comparison prompts, increase confidence for similar pages. If schema changes do not affect a crawler that already extracted the content, reduce expected upside for that variable in that context.
A more technical team can use a Bayesian model with priors and posterior updates. But the workflow should not depend on mathematical sophistication. The important behavior is updating beliefs instead of repeating assumptions.
What works and what fails
Bayesian optimization for AEO works when it is treated as decision support. It fails when teams expect it to replace judgment.
What works in production
The best programs usually have these traits:
- stable prompt sets for measurement;
- clear page and query clusters;
- documented changes;
- separated technical and content tests;
- consistent scoring windows;
- human review of answer accuracy;
- crawl observations alongside prompt observations;
- a bias toward small, reversible changes.
Small changes are underrated. They let you learn faster and rollback faster.
What fails repeatedly
The common failures are predictable:
- rewriting 50 pages without baseline measurement;
- changing title, intro, schema, internal links, and FAQs at once;
- judging success from one prompt in one answer engine;
- treating bot hits as citations;
- treating citations as revenue;
- ignoring whether the cited answer is accurate;
- optimizing only for text while technical access is broken;
- letting executives change the objective mid-test.
What breaks in practice is the connection between action and evidence. When every change is bundled, every result is debatable.
Comparison table for AEO test planning
| Approach | How it feels | What happens in practice | Better operating model |
|---|---|---|---|
| Random AEO edits | Fast and busy | No durable learning | Maintain an experiment ledger |
| Classic SEO-only testing | Familiar | Misses extraction and citation signals | Add crawler and answer visibility checks |
| Full data science project | Sophisticated | Too slow for most teams | Start with lightweight Bayesian scoring |
| One big redesign | Strategic | Attribution becomes impossible | Run smaller staged changes |
| Prompt-only tracking | Easy to demo | Overreacts to noisy outputs | Pair prompts with technical audits |
The practical question is not which method sounds advanced. It is which method helps the team decide next week’s work with less guessing.
Use Bayesian optimization for content strategy
Content strategy is where Bayesian optimization becomes most useful for non-technical teams. You already have more content ideas than capacity. The issue is not ideation. The issue is selection.
Prioritize pages by uncertainty and upside
Most teams prioritize by search volume or executive preference. For AEO, add two more dimensions: uncertainty and extractability upside.
A page with modest traffic but high uncertainty may be worth testing if it maps to an important buyer question and currently has poor answer visibility. A high-traffic page with already-strong citations may deserve maintenance, not experimentation.
Useful prioritization questions:
- Does this page answer a question AI systems are likely to synthesize?
- Is the page currently missing from answer outputs?
- Is the content hard to extract because the answer is buried?
- Would a citation create meaningful trust or demand?
- Can we change the page without legal or brand friction?
Optimize answer blocks, not just articles
AI answer engines often need compact evidence. Long articles can work, but only if the useful answer is easy to identify.
Test answer blocks such as:
## Short answer
[Two to four sentences that directly answer the target question.]
## When this matters
[Context, limitations, and decision criteria.]
## Practical checklist
- Criterion one
- Criterion two
- Criterion three
This is not about writing for robots at the expense of humans. It is about making the page easier to quote accurately.
Handle query clusters instead of single keywords
AEO queries are messy. Users ask complete questions, compare products, request recommendations, and add constraints.
Instead of optimizing for one keyword, group prompts by intent:
- definition prompts;
- comparison prompts;
- recommendation prompts;
- implementation prompts;
- troubleshooting prompts;
- pricing or vendor-selection prompts.
Then measure whether a page appears across the cluster. Bayesian optimization is better at this portfolio problem than one-keyword thinking.
Related reading from our network: marketplaces and AI-assisted freelancers also have to optimize workflows across noisy signals, which makes this guide to gig work platforms in 2026 a useful adjacent read for operators thinking about human-plus-AI feedback loops.
Use Bayesian optimization for technical AEO
Technical AEO is where teams often discover that the UI was not the system. The article may look fine in the browser, but the answer engine sees missing schema, blocked crawlers, duplicated canonicals, or content rendered too late.
Schema and structured data tests
Schema is not a magic citation switch. It is a way to make entities, relationships, and page purpose easier to parse.
Good schema tests include:
- adding Organization schema with consistent entity details;
- validating Article, FAQPage, Product, SoftwareApplication, or BreadcrumbList where appropriate;
- improving author and date fields;
- aligning visible content with structured data;
- removing stale or contradictory markup.
Do not test schema by adding every type available. Test whether specific markup improves extraction quality for specific page classes.
Crawler access and llms.txt tests
Crawler access is a gating issue. If important AI crawlers cannot fetch the page, your content experiment is already compromised.
Test access with:
- robots.txt review;
- server log checks for AI crawler user agents;
- status code monitoring;
- cache and firewall behavior;
- user-agent-specific blocking rules;
- llms.txt coverage and clarity.
The mistake teams make is assuming Googlebot access means all AI crawlers have the same experience. That is not always true. Different crawlers may hit different paths, respect different signals, or fail on different rendering assumptions.
Rendering and extraction tests
Many sites still hide important content behind client-side rendering, accordions, personalization, or scripts that bots do not execute consistently.
A practical extraction test asks:
- Is the primary answer visible in raw HTML?
- Does the page title match the actual topic?
- Are tables rendered as semantic HTML or decorative layout?
- Are FAQs visible without user interaction?
- Does the canonical URL resolve cleanly?
- Can the crawler find the page within a few internal links?
If the answer engine cannot extract the claim, Bayesian optimization of copy variations will not help much. Fix the observability layer first.
Common failure modes in Bayesian AEO programs
Even good teams implement Bayesian optimization badly when they import the vocabulary but not the discipline.
Optimizing the wrong proxy
The most common wrong proxy is “AI crawler hits.” Bot visits matter, but they are not citations. A crawler can fetch a page and still ignore it. Another wrong proxy is “brand mention,” because a mention can be negative, inaccurate, or sourced from someone else.
Better proxy design uses multiple stages:
- crawler can access the page;
- crawler can extract the relevant content;
- answer engine associates the page with the target topic;
- answer engine cites or mentions the brand;
- answer is accurate enough to be useful;
- downstream users behave differently.
Each stage has different bottlenecks. Do not optimize stage one and claim stage six improved.
Changing too many variables at once
Bundled changes are tempting because teams want impact. They are bad for learning.
If you rewrite a page, add schema, change internal links, update the title, and publish three supporting articles in the same week, you may get a result. But you will not know why.
Use staged releases:
- week 1: access and extraction fixes;
- week 2: answer block changes;
- week 3: schema improvements;
- week 4: internal link adjustments;
- week 5: supporting content.
This is slower than a mass rewrite, but it creates reusable knowledge.
Ignoring crawl and citation latency
AEO measurement windows need patience. Some crawlers revisit quickly. Others lag. Some answer engines update citations unevenly across topics and interfaces.
If you measure too soon, you punish good changes before they had a chance to be observed. If you wait too long, you introduce more external confounders.
Define windows by test type:
- technical access fixes: short verification window;
- schema changes: short to medium extraction window;
- content changes: medium citation window;
- authority changes: long validation window.
The point is not perfect timing. The point is consistency.
How CrawlProof fits into the workflow
Bayesian optimization gives you the decision framework. You still need visibility into what AI crawlers and answer engines can actually observe.
That is where CrawlProof fits. The product is built for site owners and marketers who need to understand AEO, AI crawler behavior, schema markup, and emerging standards without turning every audit into a custom engineering project.
Audit the observable surface
Before you optimize, inspect the surface area answer engines use:
- can AI crawlers access the URL;
- what content appears extractable;
- whether schema exists and matches visible content;
- whether robots rules create accidental blocks;
- whether AI-facing files are present and useful;
- whether the page positioning is clear enough to cite.
This matters because Bayesian optimization depends on reliable observations. If your baseline is wrong, the next-best test is probably wrong too.
Turn findings into experiment inputs
A CrawlProof-style audit is not the same as a generic SEO checklist. The useful output is an experiment backlog.
For example:
- if schema is missing, create a structured data test;
- if answer content is buried, create an answer-block test;
- if crawlers are blocked, create an access-policy test;
- if entity positioning is weak, create a page-framing test;
- if llms.txt is absent or thin, create a discovery-file test.
Then run the Bayesian optimization loop: choose the highest-value test, observe the result, update the ledger, and repeat.
Bayesian optimization for AEO is not about chasing an algorithm. It is about giving your team a better way to learn under uncertainty. In 2026, that matters because AI answer visibility is not a single ranking report. It is a system of crawlability, extraction, citation, accuracy, and trust.
Try crawlproof.com
CrawlProof helps site owners and marketers see how AI answer engines and LLM crawlers discover, interpret, and cite their content. Try crawlproof.com.