
Cloud computing answer engine optimization sounds like a niche SEO phrase until your best cloud infrastructure page stops showing up in AI answers.
The page ranks. It loads for humans. Search Console looks normal. But when an answer engine summarizes options, explains concepts, or cites sources, your content is missing or reduced to a vague mention.
Teams think the problem is content quality. The real problem is retrieval reliability.
If your website depends on cloud hosting, CDNs, JavaScript rendering, edge redirects, personalization, API-fed content, or aggressive bot filtering, then AEO is an architecture and workflow problem. The practical question is not whether AI systems like your brand. It is whether their crawlers can fetch, parse, trust, and reuse your content consistently enough to cite it.
Table of contents
- What cloud computing answer engine optimization really means
- Why cloud-hosted sites lose citations even with decent SEO
- Build a crawlable cloud delivery path
- Schema, llms.txt, and machine-readable contracts
- Performance and availability for AI crawlers
- Content architecture for cloud computing answer engine optimization
- Workflow: validate how answer engines see your cloud site
- What breaks when teams implement AEO badly
- Ownership across SEO, engineering, and cloud operations
- Make cloud computing answer engine optimization measurable
What cloud computing answer engine optimization really means
Cloud computing answer engine optimization is the practice of making cloud-hosted websites, documentation, product pages, and knowledge assets reliably discoverable by AI answer engines. That includes traditional SEO inputs, but it also includes crawl behavior, server responses, structured data, content stability, bot visibility, and the way cloud delivery systems expose information.
The mistake teams make is treating AEO as a copywriting layer. They add FAQ sections, rewrite intros, and chase prompt-friendly phrasing. Some of that helps. But if an AI crawler gets a 403 from your WAF, sees a half-rendered shell, misses schema because it is injected late, or receives different content by geography, the copy never gets a fair read.
Why answer engines evaluate infrastructure indirectly
Answer engines do not only consume pages like a human reader. They retrieve, parse, chunk, summarize, and compare sources. They may use search indexes, direct crawlers, partner feeds, cached snapshots, or model-side retrieval systems. You rarely control the full path.
You do control the signals exposed by your cloud stack:
- HTTP status codes and redirects
- robots.txt and emerging llms.txt guidance
- canonical URLs
- schema markup
- sitemap quality
- server-rendered HTML
- CDN cache behavior
- bot allowlists and rate limits
- page freshness signals
- content consistency across regions
That changes the conversation. AEO is not only about being persuasive. It is about being easy to retrieve without ambiguity.
The practical architecture shift
A useful way to think about it is this: your website now has at least two user journeys. One is the human journey through UI, navigation, forms, and conversion paths. The other is the machine journey through source discovery, fetch, parsing, citation, and answer generation.
Those journeys overlap, but they are not identical. A human can tolerate a cookie banner, lazy-loaded tabs, pricing behind a selector, and animated UI. A crawler may not.
Practical rule: if a fact is important enough to be cited by an answer engine, it should exist in stable HTML and structured metadata without requiring a fragile client-side journey.
For cloud businesses, developer tools, SaaS platforms, hosting providers, marketplaces, and technical publishers, that means AEO belongs in the same planning room as SEO, frontend engineering, cloud operations, and content strategy.
Why cloud-hosted sites lose citations even with decent SEO
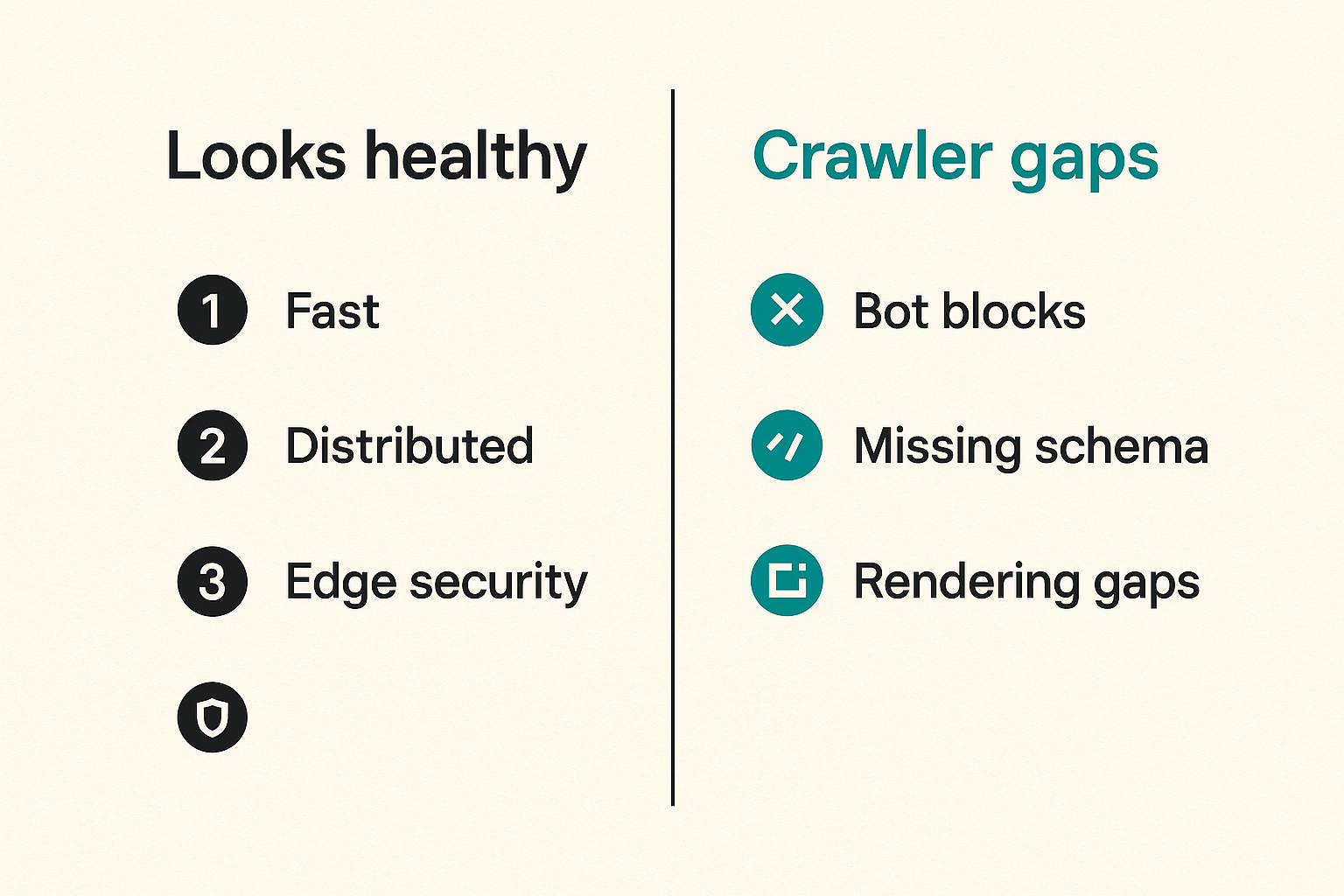
Cloud-hosted sites often look healthy from the outside. They are fast, globally distributed, protected by edge security, and assembled from modern frameworks. But those same advantages can create AEO failure modes.
The problem is rarely one dramatic outage. It is usually small inconsistencies: a crawler blocked on one path, schema missing on another, canonical tags changing by template, or a CDN returning stale content after an update.
Crawl access is not the same as answer eligibility
Many teams check whether Googlebot can crawl a page and assume the work is done. That is too narrow. AI answer engines and LLM retrieval systems may use different bots, different crawl frequencies, and different tolerance for errors.
A page can be accessible and still be a weak source if:
- The main answer is buried under boilerplate
- The page depends on client-side rendering
- The content conflicts with schema
- The title promises one topic but the body covers another
- The page changes too frequently for stable citation
- The bot receives a different response than normal users
Answer eligibility is about usefulness under retrieval conditions. That includes technical access, but also clarity, extractability, and trust.
Rendering and edge logic create invisible gaps
Modern cloud delivery often includes middleware, geolocation, A/B testing, language negotiation, bot detection, consent tools, and personalization. These are reasonable for product operations. They are dangerous when they alter core content for crawlers.
What breaks in practice is consistency. One bot sees a redirected regional page. Another sees a consent wall. A third gets a JavaScript app shell with no meaningful body. Your team sees the correct page in a browser and assumes the problem is external.
Common cloud-specific issues include:
- Edge functions rewriting URLs without preserving canonicals
- WAF rules challenging unfamiliar AI crawler user agents
- CDN cache keys varying by headers that bots do not send
- Hydration failures hiding body copy or schema
- Serverless cold starts creating intermittent 5xx responses
- Staging headers accidentally copied into production templates
This is why cloud computing answer engine optimization has to inspect the delivery path, not just the rendered design.
Build a crawlable cloud delivery path
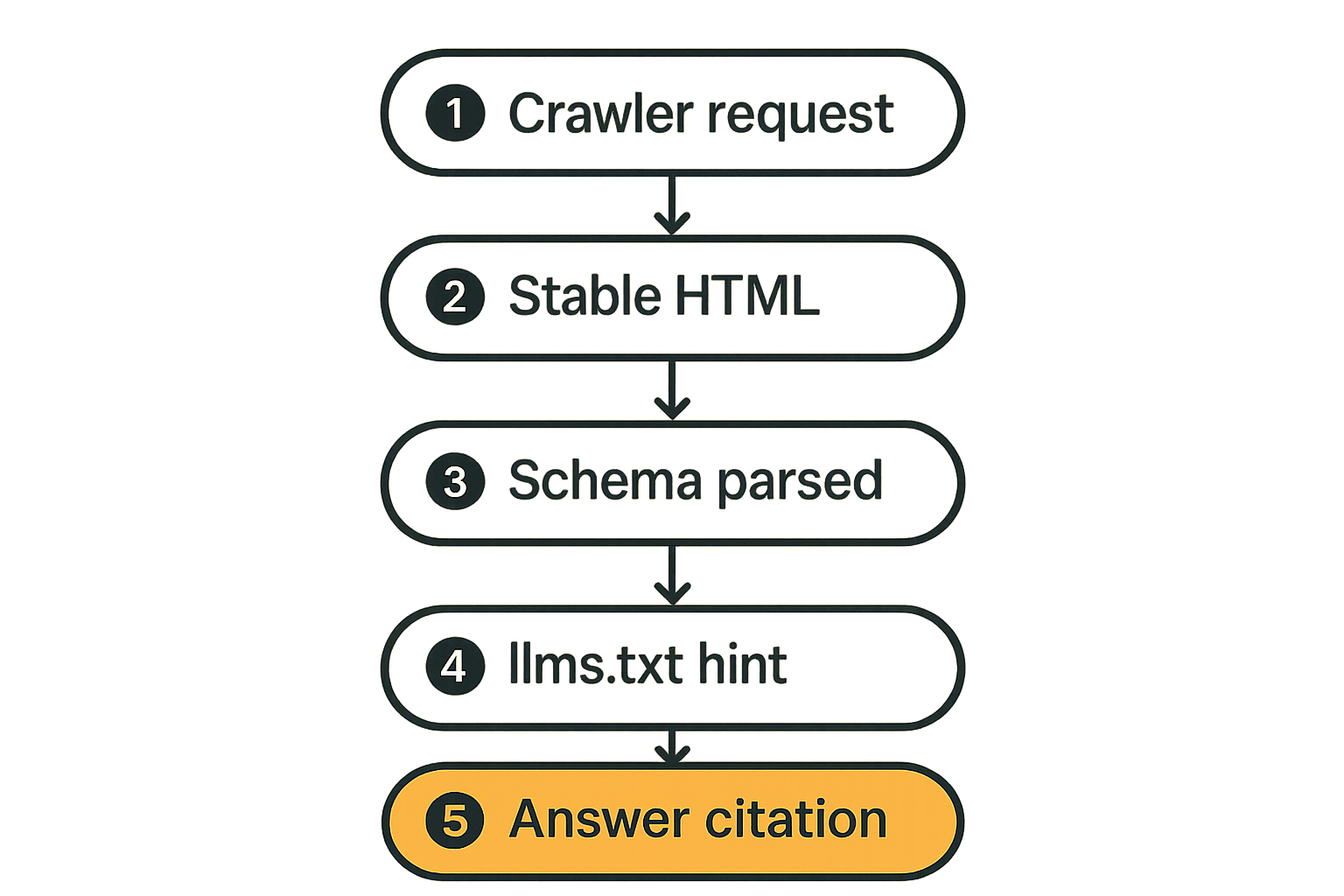
Before you optimize content, make the delivery path boring. Boring is good. Boring means deterministic, inspectable, cacheable, and easy to debug.
For AI crawlers, the best path is usually the least clever path: a stable URL that returns a 200, includes the primary content in HTML, exposes schema, points to a canonical, and does not require interaction to reveal the answer.
Keep the canonical path boring
Cloud teams often route traffic through layers: DNS, CDN, edge middleware, application gateway, frontend framework, API services, and third-party scripts. Every layer can change what a crawler sees.
A practical canonical path should have:
- One preferred HTTPS URL
- Minimal redirect hops
- A stable canonical tag
- Server-rendered or pre-rendered primary content
- No bot challenge for known legitimate crawlers
- No dependency on user session state for public facts
- Predictable cache behavior
Practical rule: the crawler version of a public knowledge page should not depend on cookies, viewport events, local storage, or a pricing toggle to expose the answer.
That does not mean every page needs to be static. It means the information you want cited should be available without running your whole application state machine.
Separate user personalization from machine-readable facts
Personalization is useful for conversion. It is not a reliable base for citation.
If your cloud pricing page changes by region, plan, usage tier, or logged-in state, keep a stable explanatory layer above the calculator. If your product page adapts by industry, keep the core definition, capabilities, limits, and use cases consistent. If your docs load API examples dynamically, ensure the default examples are visible in HTML and schema.
A simple pattern works well:
| Layer | Human purpose | AEO purpose | Implementation note |
|---|---|---|---|
| Stable summary | Orient the reader | Give answer engines a quoteable source | Keep in server-rendered HTML |
| Structured facts | Support parsing | Clarify entities and relationships | Use schema consistently |
| Interactive tools | Convert or educate | Secondary signal only | Do not hide core claims here |
| Personalized modules | Improve relevance | Risk of inconsistency | Keep separate from canonical facts |
The goal is not to remove dynamic cloud experiences. The goal is to prevent dynamic behavior from becoming the only source of truth.
Schema, llms.txt, and machine-readable contracts
Structured data and llms.txt are not magic switches. They are contracts. They tell machines what a page is, what it contains, and how it should be approached.
The mistake teams make is treating these files as decorations. They add schema once, forget it, and never check whether it still matches the page. Or they publish llms.txt as a marketing page instead of a routing layer for machine readers.
Treat structured data as an interface
Schema markup should reflect the actual content visible on the page. For cloud computing pages, useful types often include Organization, Product, SoftwareApplication, FAQPage where appropriate, Article, TechArticle, HowTo, BreadcrumbList, and Dataset if the page publishes structured reference material.
The practical question is: what should a machine know without guessing?
For example, a cloud backup vendor might expose:
- Product name and category
- Supported platforms
- Pricing page relationship
- Documentation links
- FAQ questions and answers
- Author or publisher identity
- Last modified date
- Breadcrumb hierarchy
Do not over-markup. Do not claim every page is an FAQ. Do not hide claims in JSON-LD that are absent from visible content. Answer engines are built to compare signals, and inconsistency weakens trust.
Use llms.txt as a routing hint not a ranking hack
llms.txt is emerging as a way to help AI systems locate useful machine-readable content. It should be concise, maintained, and aligned with your public content strategy.
A practical llms.txt for a cloud business might point to:
- Core product explanations
- Technical documentation
- API references
- Pricing and plan pages
- Security and compliance pages
- Changelogs
- Glossaries
- Canonical comparison pages
Keep it operational. If you would not want a sales engineer, support agent, or developer advocate relying on a page, do not make it a top machine-readable entry point.
Here is a simplified pattern:
# Example llms.txt structure
# Company
https://example.com/about
https://example.com/security
# Product
https://example.com/cloud-storage
https://example.com/cloud-storage/pricing
https://example.com/docs/cloud-storage
# Reference
https://example.com/docs/api
https://example.com/changelog
https://example.com/glossary
Practical rule: llms.txt should reduce crawler guesswork. It should not become a junk drawer of every URL your CMS can export.
Performance and availability for AI crawlers
Speed still matters, but AEO performance is not only Core Web Vitals. AI crawlers care whether they can retrieve the content reliably at crawl time.
A slow page is bad. An intermittently unavailable page is worse. A page that works for humans but fails for bots is the hardest to detect unless you are watching crawler-specific behavior.
Optimize for repeatable retrieval
Cloud infrastructure introduces variable conditions. Serverless functions can cold start. API-backed pages can time out. CDN purges can race with deploys. Regional edge nodes can serve different versions. None of this is unusual in production.
For answer engines, repeatability is the signal. If the crawler returns tomorrow and sees a different title, missing schema, or a 503, your source becomes less dependable.
Good retrieval hygiene includes:
- Low redirect count
- Conservative timeout budgets for public pages
- Static generation for evergreen reference content
- Cached schema and body content
- Graceful degradation when APIs fail
- Monitoring by user agent and status code
- Separate alerts for bot-facing 4xx and 5xx spikes
This is where cloud operations and AEO meet. An SEO team may see no ranking issue yet, while the crawl layer is already degrading.
Watch bot-specific failure patterns
Bot traffic is easy to misread. Some bots are abusive. Some are legitimate. Some impersonate others. AEO does not mean opening your infrastructure to everything that sends a crawler-like user agent.
It does mean you need a policy.
Classify crawler traffic into at least four groups:
| Crawler group | Default action | What to monitor |
|---|---|---|
| Known search bots | Allow with verification | Status codes, crawl depth, canonical fetches |
| Known AI crawlers | Allow if aligned with policy | Access to public knowledge pages |
| Unknown high-rate bots | Rate limit or challenge | Request bursts, path patterns |
| Suspicious agents | Block | Spoofing, credential probes, exploit paths |
For cloud computing answer engine optimization, the important point is not to allow every bot. It is to avoid accidentally blocking the machines you expect to understand your content.
Content architecture for cloud computing answer engine optimization
AEO content is not a pile of FAQs. It is an information architecture designed for extraction.
Answer engines prefer sources that resolve ambiguity. They need to identify the entity, understand the claim, compare it with other sources, and decide whether it is useful in an answer. Cloud computing content often fails here because it assumes too much context.
Answer pages need stable claims
A strong AEO page makes clear claims in stable language. For cloud topics, that means defining the service, use case, architecture, limitations, and decision criteria without forcing the reader through five related posts.
Good pages usually include:
- A direct explanation near the top
- Clear entity names and product names
- Definitions of technical terms
- Practical use cases
- Limitations and tradeoffs
- Links to documentation or references
- Freshness signals when details change
The team at c0mpute.com, working around decentralized compute, AI inference, transcoding, and DID-based payment flows, sees this problem often: technical systems are easy to describe to builders, but harder to expose as stable machine-readable knowledge.
That lesson applies broadly. If your cloud page depends on insider vocabulary, answer engines may summarize it poorly or choose a clearer competitor.
Make cloud concepts easy to quote
Answer engines do not need your entire brand narrative. They need extractable explanations.
For example, instead of writing:
Our platform unlocks next-generation workload agility across modern digital transformation initiatives.
Write:
The platform runs containerized workloads on distributed GPU nodes and is designed for batch AI inference, media transcoding, and burst compute jobs.
The second sentence gives entities, workloads, constraints, and use cases. It is easier for a retrieval system to classify and cite.
A useful structure for cloud pages:
- What it is
- Who it is for
- How it works
- When to use it
- When not to use it
- Operational requirements
- Security or compliance notes
- Pricing or settlement model, if relevant
This is not only good for AI. It is good for buyers who are tired of vague cloud positioning.
Workflow: validate how answer engines see your cloud site
Most AEO programs fail because validation happens too late. Teams publish content, wait for AI visibility, then guess why citations did not appear.
The better workflow is to test machine access before and after publication. Treat AI crawler visibility like a release checklist.
A practical implementation sequence
Use this sequence for important cloud pages, especially product, docs, pricing, comparison, and glossary pages:
- Select canonical pages. Identify the URLs you actually want answer engines to use.
- Check server responses. Confirm 200 status, low redirects, correct canonical tags, and stable HTML.
- Inspect rendered and raw HTML. Verify the primary answer exists before interactive UI is required.
- Validate schema. Ensure JSON-LD matches visible content and uses appropriate types.
- Review robots and llms.txt. Confirm crawl guidance is intentional and not inherited from old rules.
- Test bot access. Review logs for AI crawler user agents and status codes.
- Compare regions. Fetch pages through different edge locations if your CDN varies responses.
- Monitor after deploys. Watch for schema regressions, blocked bots, and 5xx spikes.
- Refresh content deliberately. Update facts, dates, and structured data together.
This is a workflow, not a one-time audit. Every framework upgrade, CDN rule, WAF change, or CMS migration can affect AEO.
What to test before publishing
Before publishing a cloud computing AEO page, ask practical questions:
- Can a crawler understand the page without JavaScript?
- Is the core claim visible in the first meaningful content block?
- Does schema match the body copy?
- Are internal links pointing to supporting reference pages?
- Are duplicate URLs canonicalized?
- Does the page return the same core content across regions?
- Are bots rate-limited differently from browsers?
- Does the page still work when third-party scripts fail?
Practical rule: if your AEO validation requires a human to click, expand, accept, filter, or log in, the machine-readable version is probably too fragile.
The point is not to make every page plain. The point is to make essential public knowledge resilient.
What breaks when teams implement AEO badly
Bad AEO is usually overconfident. It assumes answer engines behave like search engines, assumes schema will fix weak pages, or assumes cloud infrastructure is neutral.
What breaks in practice is the chain between content intent and machine retrieval.
Failure modes that look like content problems
Many AEO failures are misdiagnosed as editorial issues. Teams rewrite pages when the actual problem is access, parsing, or inconsistency.
Watch for these patterns:
- The page ranks but is not cited. Possible cause: content is indexed by search but not easy for answer engines to extract.
- AI answers cite old copy. Possible cause: stale CDN cache, outdated sitemap dates, or inconsistent canonical paths.
- Competitors are cited for your branded concept. Possible cause: your own explanation is too vague or blocked.
- Docs are visible but product pages are ignored. Possible cause: docs are static and product pages are dynamic shells.
- Schema validates but answers are wrong. Possible cause: structured data conflicts with visible content.
- Bot logs show low crawl depth. Possible cause: rate limits, redirect chains, or poor internal linking.
The mistake teams make is optimizing the page they see, not the page the machine gets.
What works and what fails
AEO rewards operational clarity. It punishes disconnected tooling.
| Area | What fails | What works |
|---|---|---|
| Content | Vague positioning and buried definitions | Direct answers with stable claims |
| Rendering | JavaScript-only body content | Server-rendered or pre-rendered core content |
| Schema | Generic markup added once | Maintained metadata that matches the page |
| Cloud delivery | Bot challenges and inconsistent edge responses | Predictable fetch path with monitored logs |
| Governance | SEO owns everything alone | Shared ownership across SEO, content, dev, and ops |
| Measurement | Waiting for mentions manually | Tracking crawl access, schema health, and citations |
There is no single AEO plugin that fixes this. Plugins can help with schema or metadata. They cannot decide whether your CDN is serving three different versions of your pricing page to different crawlers.
Ownership across SEO, engineering, and cloud operations
Cloud computing answer engine optimization cuts across teams. If ownership is unclear, every problem becomes someone else's backlog.
SEO sees missing visibility. Content sees unclear pages. Developers see rendering constraints. Cloud operations sees bot traffic and security rules. Legal may care about claims. Product may own pricing logic. All of them can affect whether answer engines cite your site.
Define the handoffs
A practical ownership model looks like this:
| Team | Owns | AEO responsibility |
|---|---|---|
| SEO/content | Page strategy and entity coverage | Define target queries, claims, and canonical pages |
| Engineering | Rendering and templates | Ensure core content and schema are reliable |
| Cloud/DevOps | CDN, WAF, logs, uptime | Monitor crawler access and response consistency |
| Product | Feature and pricing truth | Keep public claims accurate |
| Analytics | Measurement | Track visibility, citations, and crawl health |
This table matters because AEO problems often cross boundaries. A content strategist cannot fix a WAF rule. A DevOps engineer cannot decide which comparison page should be canonical. A developer cannot validate product claims alone.
Use incidents to improve answer visibility
Treat major AEO regressions like lightweight incidents. You do not need a war room for every missing citation, but you do need a record of what changed.
Useful incident questions:
- Did a deploy change templates or schema?
- Did a CDN rule alter cache behavior?
- Did a WAF update block crawlers?
- Did content move without redirects?
- Did robots.txt or llms.txt change?
- Did a page become dependent on a failing API?
AEO maturity comes from closing the loop. When a failure happens, update the checklist, monitoring, and release process so the same issue does not repeat.
Make cloud computing answer engine optimization measurable
Cloud computing answer engine optimization should not be managed by vibes. You will not get perfect visibility into every model or retrieval system, but you can measure the inputs that make citation more likely.
The goal is to reduce uncertainty. You want to know whether machines can access your pages, whether your content is structured, whether your cloud stack is consistent, and whether answer visibility is improving over time.
Metrics that matter
Start with operational metrics before trying to attribute every AI mention:
- Crawlable canonical pages
- Bot status code distribution
- AI crawler access by path
- Redirect depth on important URLs
- Schema coverage and validation errors
- llms.txt freshness and URL coverage
- Pages with server-rendered primary content
- Content freshness for key cloud topics
- AI answer mentions and citation quality
- Mismatches between cited pages and intended pages
These metrics are not glamorous, but they are useful. They show whether your site is becoming easier for answer engines to retrieve and trust.
A practical dashboard might group signals into three buckets: access, understanding, and outcomes. Access covers whether crawlers can fetch the page. Understanding covers schema, headings, entities, and content clarity. Outcomes cover citations, mentions, and answer quality.
Where CrawlProof fits
CrawlProof is useful when you want AEO to become an operating system instead of a quarterly audit. For site owners, SEO professionals, content strategists, and developers, the hard part is not knowing that AI crawlers matter. The hard part is seeing how crawlers interact with your actual website and what needs to change.
In a cloud-hosted environment, that means connecting content decisions to crawler behavior, schema health, llms.txt guidance, and technical accessibility. The product fit is architectural: make the machine-readable path observable, then improve it page by page.
That is the sane way to approach cloud computing answer engine optimization in 2026. Not as hype. Not as a prompt trick. As a crawl, content, and infrastructure workflow that makes your public knowledge easier to find, parse, and cite.
Try crawlproof.com
CrawlProof helps websites understand AEO, AI crawler behavior, schema markup, and emerging standards like llms.txt. If cloud computing answer engine optimization matters to your site, Try crawlproof.com.