
If you run a peptide research site, a supplier directory, or any technical health-science property, you've probably noticed something unsettling: AI answer engines are answering detailed questions about peptides — BPC-157 half-life, TB-500 dosing windows, synthesis purity standards — and your site isn't in the citations. Someone else is. Often a forum thread. Sometimes a three-year-old Reddit post. Occasionally nothing at all, just confident synthesis from a model that learned from data you can't trace.
That's not a content quality problem. Your content may be more accurate, more detailed, and better sourced than anything the LLM is surfacing. The problem is architectural. AI answer engines — systems like Perplexity, ChatGPT with search, Gemini, and the retrieval layers being built into every search surface — don't discover and cite content the way Google crawlers do. The signals are different. The trust heuristics are different. The structured data requirements are different.
Teams think the problem is that they need more content. The real problem is that their existing content isn't readable by retrieval-augmented generation (RAG) pipelines, isn't structured for answer extraction, and isn't signaling the right trust markers to the models that decide what gets cited.
This post unpacks that architecture problem specifically for specialized, technical niches — using peptide content as the working example — and gives you a concrete workflow for fixing it.
Table of contents
- Why peptide content is a useful stress test for AEO
- How AI answer engines actually retrieve and cite content
- The structural signals that determine citation
- llms.txt and what it actually does for specialized sites
- Content chunking: how LLMs read your pages
- Trust signals AI answer engines use in specialized niches
- Common failure modes: what breaks in practice
- A practical AEO audit workflow for peptide and technical niche sites
- Comparison: traditional SEO versus answer engine optimization for technical niches
- Where crypto and payments infrastructure content faces the same problem
- Product fit: making your technical content crawlproof
Why peptide content is a useful stress test for AEO
Peptide content sits at an interesting intersection: it's highly technical, it exists in a contested regulatory space, and the audience asking questions ranges from academic researchers to bodybuilding forums to legitimate clinical practitioners. That mix makes it one of the harder problems in answer engine optimization, and solving it teaches you principles that apply to any specialized niche.
The practical question is: why would an AI answer engine cite your peptide content over someone else's? And why does it so frequently cite lower-quality sources?
Technical depth versus citation likelihood
There's a counterintuitive dynamic in technical niches: the deeper and more nuanced your content, the harder it often is for a RAG pipeline to extract a clean, citable answer from it. A page that carefully explains that BPC-157 stability varies by lyophilization method, pH of reconstitution buffer, and storage temperature is more accurate than one that just says "store at -20°C in bacteriostatic water" — but the latter is far more likely to get cited because it produces a clean, extractable answer chunk.
The mistake teams make is optimizing for human comprehension without also optimizing for machine extraction. These aren't the same thing, and for specialized technical content they diverge significantly.
The regulatory gray zone problem
Peptides occupy a legal gray zone in many jurisdictions — research chemicals, not approved therapeutics in most markets. AI systems have learned to be cautious here. Many answer engines apply content filtering or citation avoidance for anything that reads like medical advice or unregulated supplement promotion. If your content doesn't clearly signal its framing — research context, supplier directory, regulatory compliance information — it may be deprioritized as a citation source regardless of its quality.
This is a structural problem, not a content problem. The fix is in how you signal intent and framing through markup and page architecture, not just through prose.
Practical rule: For content in regulatory gray zones, explicitly frame the context in metadata, schema markup, and the opening paragraph. "Research use only" or "regulatory compliance information" as explicit structured signals helps AI systems categorize your content correctly rather than defaulting to avoidance.
How AI answer engines actually retrieve and cite content
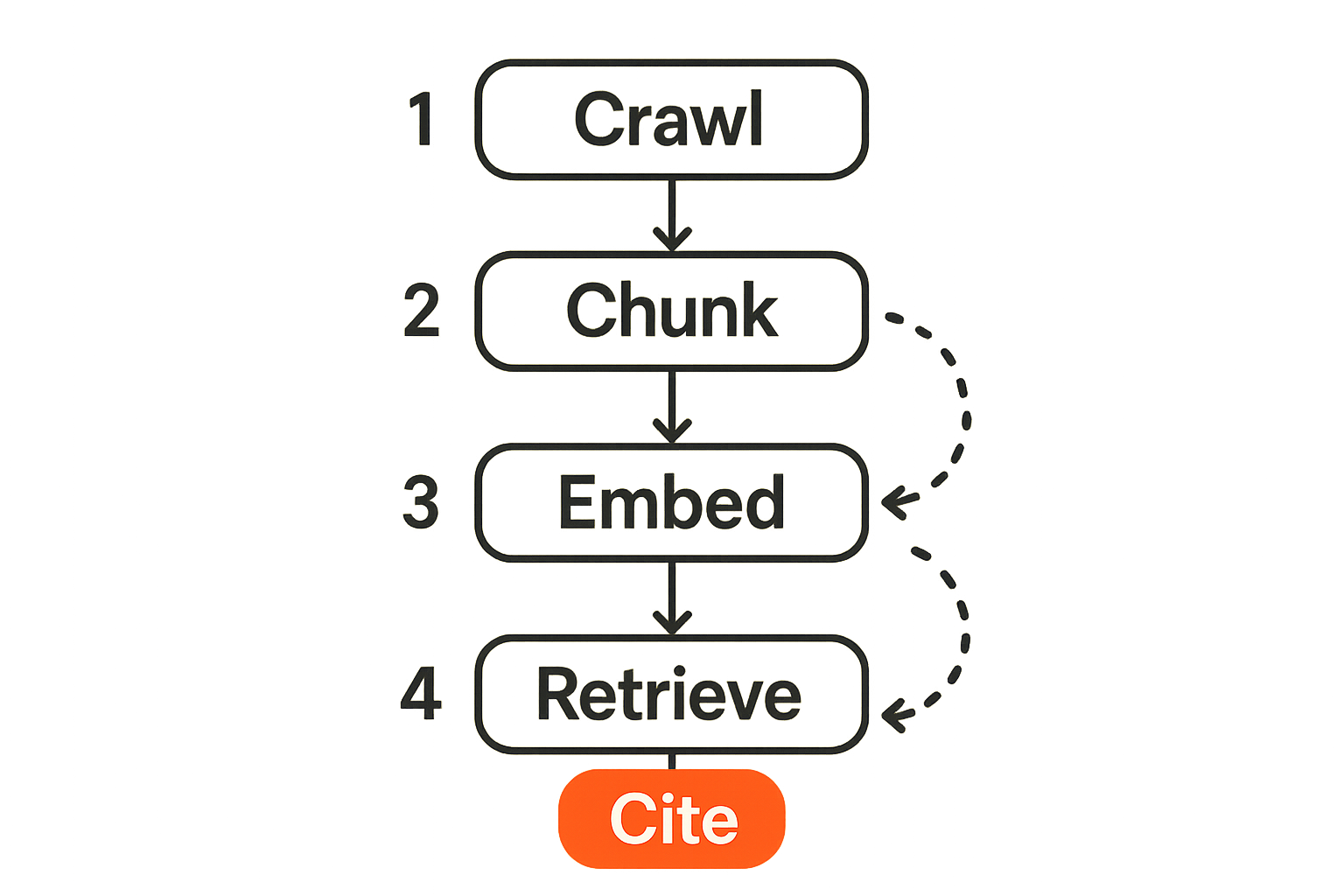
Crawling versus retrieval: two different pipelines
The mistake teams make when approaching AEO is treating it like traditional SEO with different keywords. The crawling and retrieval pipeline for an AI answer engine is architecturally different from Googlebot.
A traditional search crawler indexes the page, runs ranking signals, and surfaces it in results where a human clicks through. An AI answer engine runs a retrieval-augmented generation pipeline: it embeds your content into vector space, retrieves relevant chunks when a query fires, and uses those chunks as context for the LLM to generate an answer. Your citation happens (or doesn't) at the chunk retrieval step, not the page ranking step.
That changes the conversation entirely. You're not optimizing for page rank — you're optimizing for chunk relevance and extraction fidelity.
What RAG pipelines look for when chunking your pages
RAG systems typically chunk content by paragraph, heading boundary, or token limit (often 256–512 tokens per chunk). Each chunk is embedded and stored independently. When a query comes in, the system retrieves the top-k most semantically relevant chunks and feeds them to the LLM as context.
What this means in practice:
- Each chunk needs to be self-contained enough to answer a question without requiring the surrounding context
- Heading structure directly affects chunk boundaries — a chunk that starts mid-thought after an H3 boundary is harder to extract cleanly
- Dense prose that relies on context from three paragraphs back will chunk badly
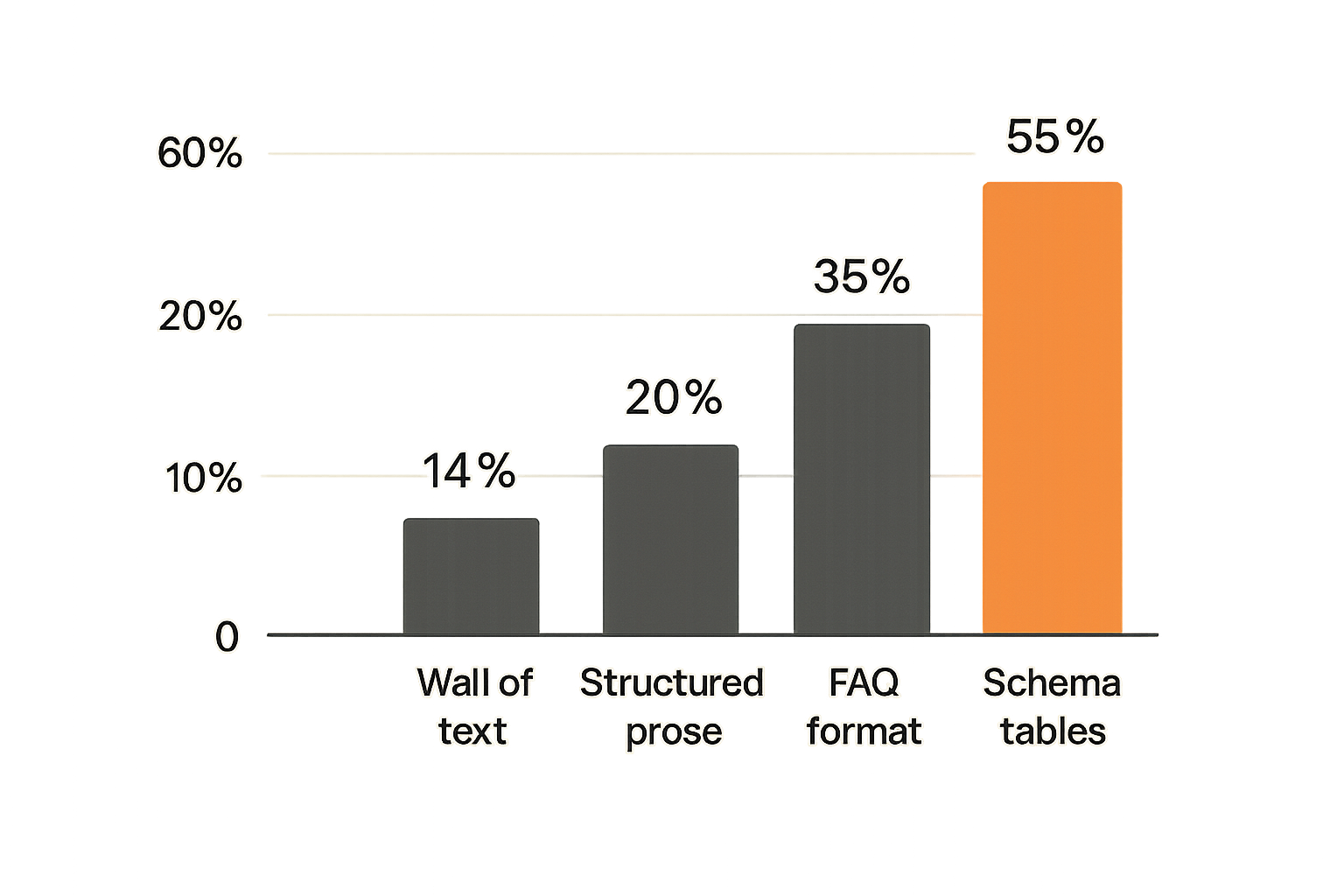
- Tables, definition lists, and Q&A-formatted content chunk very well
Practical rule: Write every H3 section so the first two sentences could stand alone as a citation. The rest of the section adds depth, but the opening must be extractable.
The structural signals that determine citation
Schema markup for technical and scientific content
For peptide content and other technical niche sites, the most impactful schema types are ones most site owners in this space haven't implemented:
- MedicalWebPage or MedicalScholarlyArticle for research-framed content
- Drug schema (where applicable) for peptide compound pages, including properties like
nonProprietaryName,activeIngredient, andwarning - FAQPage schema on any page that addresses common questions — this remains one of the most reliably extracted schema types for RAG pipelines
- HowTo schema for protocols and procedures
- DefinedTerm and DefinedTermSet for glossary-style content
The mistake teams make is implementing only Article or BlogPosting schema and calling it done. For technical niches, the specificity of your schema type is itself a trust signal. A page marked up as MedicalWebPage with explicit audience and about properties is far more parseable by an AI system trying to categorize your content.
Entity clarity and disambiguation
AI answer engines are entity-resolution systems as much as they are text retrievers. When you write about "BPC-157" you need to be explicit that this is a synthetic pentadecapeptide with the IUPAC name (Gly-Glu-Pro-Pro-Pro-Gly-Lys-Pro-Ala-Asp-Asp-Ala-Gly-Leu-Val), a research compound designation, and distinct from other growth factor peptides. If your page doesn't resolve this entity clearly, the model may conflate it, skip it, or cite a clearer source.
Entity markup via sameAs linking to authoritative sources (PubChem, UniProt, or relevant research databases) is one of the most underused tools for improving AI citation rates in technical niches.
llms.txt and what it actually does for specialized sites
What to put in llms.txt for a technical niche site
llms.txt is an emerging convention — not yet a ratified standard, but increasingly respected by AI crawlers — that lets you give LLM systems a curated, machine-readable index of your most important content. Think of it as robots.txt plus a site map, but written for language model consumption rather than traditional crawlers.
For a peptide site, a well-constructed llms.txt does several things:
- Signals which pages represent your authoritative content (compound reference pages, research protocol summaries)
- Provides brief context about each page's purpose and framing
- Can include explicit notes about content category ("research use only", "supplier compliance data") that help AI systems categorize your content correctly
- Lists your most structured, extractable content prominently so crawlers prioritize it
A minimal but useful llms.txt entry for a peptide compound page looks like:
# Peptide Reference Database
> Research-grade peptide compound data for scientific and regulatory use
## Compound Reference Pages
- [BPC-157 Compound Data](/peptides/bpc-157): Stability, reconstitution, purity standards. Research use only.
- [TB-500 Reference](/peptides/tb-500): Thymosin beta-4 fragment data, structural properties.
What llms.txt does not fix
Here's what teams often misunderstand: llms.txt improves discoverability and framing, but it doesn't fix bad content structure. If your compound pages are walls of unstructured prose, adding an llms.txt pointer to them doesn't make them more extractable. The RAG pipeline still has to chunk and embed what's there. llms.txt is a navigation aid, not a content quality proxy.
Practical rule: Fix your content structure first. Add llms.txt second. In that order, you get compounding benefit. In the reverse order, you're just making it easier for AI systems to find content they still can't cite well.
Content chunking: how LLMs read your pages
The paragraph-as-answer pattern
The most reliable pattern for AEO in technical niches is what you might call the paragraph-as-answer structure. Each paragraph — especially under an H3 — opens with a direct statement that could serve as a standalone answer, then adds supporting detail, caveats, and evidence.
This isn't just about short paragraphs. It's about front-loading the answerable claim. Compare these two openings for a section on BPC-157 storage:
Poorly structured (for extraction):
"When considering the storage requirements for peptide compounds, a number of factors related to the biochemical stability of the specific peptide chain must be taken into account, including..."
Well structured (for extraction):
"BPC-157 should be stored lyophilized at -20°C, away from light. Once reconstituted in bacteriostatic water, use within 30 days under refrigeration."
The second version chunks cleanly. The first requires the surrounding context to be useful, which means it often won't be cited even if the downstream detail is better.
Tables, definitions, and structured lists
Tables and definition lists are among the most citation-friendly structures in technical content. For peptide sites, the high-value structured content includes:
- Comparison tables (half-life across administration routes, stability by storage condition)
- Definition blocks for compound names and synonyms
- Numbered protocol steps with explicit parameters
- Property tables (molecular weight, sequence, CAS number)
These structures chunk predictably, embed semantically well, and produce clean extracted answers. If your compound pages don't have these, they should.
Trust signals AI answer engines use in specialized niches
Author and organization markup
In health-science and research niches, author credentialing matters to AI citation systems more than in general content categories. Pages with explicit author schema — including professional credentials, institutional affiliations, and sameAs links to researcher profiles — are treated with higher citation confidence by many answer engine systems.
The practical implementation:
{
"@type": "Person",
"name": "Dr. Jane Researcher",
"jobTitle": "Research Biochemist",
"affiliation": {"@type": "Organization", "name": "Institute for Peptide Research"},
"sameAs": "https://orcid.org/0000-0000-0000-0000"
}
For sites without credentialed individual authors, Organization schema with explicit description, areaServed, and knowsAbout properties does some of this work — less effectively, but meaningfully.
Citation chains and external references
AI systems have learned that content which cites authoritative external sources is more likely to be accurate. In practice, this means:
- Linking to primary research (PubMed, preprint servers) rather than summarizing without citation
- Using
citationschema properties on research-based claims - Making your reference structure machine-readable, not just human-visible
This is a place where many peptide content sites are leaving citation equity on the table. They summarize research accurately but don't create the machine-readable citation chain that signals to AI systems: "this content is grounded in verifiable sources."
Common failure modes: what breaks in practice
The wall-of-text problem
The most common failure mode in technical niche content: dense, expert-level prose with no structural hierarchy. This content is often genuinely authoritative. Biochemists and researchers write this way naturally — full paragraphs, complex sentences, careful qualification. But it chunks badly, embeds as a semantic soup, and gets outcompeted for citations by simpler, less accurate content that happens to be better structured.
The fix is not to dumb down the content. It's to add structural scaffolding — headings, definition blocks, property tables, summary sentences — that gives the RAG pipeline extraction anchors without removing the depth.
Missing entity disambiguation
Peptide nomenclature is genuinely confusing. BPC-157 has multiple synonyms (PL 14736, pentadecapeptide BPC, Gly-Glu-Pro-Pro-Pro-Gly-Lys-Pro-Ala-Asp-Asp-Ala-Gly-Leu-Val). TB-500 is a fragment of thymosin beta-4 but is often confused with the full protein. If your pages don't explicitly resolve these entity relationships in structured markup, AI systems may cite your content for the wrong query or skip it for the right one.
Blocking the wrong crawlers
Many site owners, concerned about AI training data scraping, have added broad robots.txt or meta noindex directives that inadvertently block the retrieval crawlers used by answer engines — which are not the same as training data harvesters.
PerplexityBot, GPTBot in retrieval mode, and similar answer engine crawlers operate differently from the crawlers used to build training corpora. Blocking them because you're worried about training data scraping is a category error. You end up invisible to citation pipelines while probably not meaningfully impacting training data collection anyway (which largely happened years ago).
What works: Use llms.txt to signal content you want cited. Use robots.txt conservatively and check which specific bot user agents you're actually blocking before deploying broad disallow rules.
A practical AEO audit workflow for peptide and technical niche sites
Step-by-step: from invisible to citable
Crawl your own site from an LLM's perspective. Use a tool that shows you how your pages chunk and what a RAG pipeline would extract. Ask: does each chunk stand alone as a useful answer?
Audit your schema coverage. For every compound or technical reference page, check whether you have appropriate schema type, author/organization markup,
sameAsentity links, and FAQPage or HowTo where applicable.Resolve entity ambiguity. For each key term in your content, add explicit disambiguation — synonyms, registry IDs,
sameAslinks to authoritative databases. Do this in schema and in the first paragraph of each page.Implement the paragraph-as-answer pattern. Audit your top 20 pages for front-loaded, extractable opening sentences under each H3. Rewrite openings that bury the direct answer.
Add structured data tables. For compound pages, add property tables (molecular weight, sequence, storage conditions, purity standards). These chunk predictably and are high-value extraction targets.
Write and deploy llms.txt. Curate your most authoritative, best-structured pages. Provide brief, accurate context descriptions. Explicitly note content framing (research use, regulatory compliance, etc.).
Audit your robots.txt and meta directives. Identify any broad AI crawler blocks. Distinguish between training data harvesters and retrieval crawlers. Remove or scope blocks appropriately.
Test against live answer engines. Query Perplexity, ChatGPT with search, and Gemini for your key questions. Note which sources are cited. Analyze the structural and markup differences between those sources and your pages.
Iterate on chunk quality. Based on what you see in step 8, identify the specific structural patterns in cited content and replicate them on your pages.
Comparison: traditional SEO versus answer engine optimization for technical niches
| Dimension | Traditional SEO | Answer Engine Optimization |
|---|---|---|
| Optimization target | Page rank in SERP | Chunk relevance in RAG retrieval |
| Content unit | Full page | Individual paragraph / section |
| Crawl signal | Link graph, indexation | Schema type, entity markup, chunk structure |
| Citation trigger | User clicks through | LLM extracts and cites chunk |
| Schema priority | Article, BreadcrumbList | FAQPage, MedicalWebPage, DefinedTerm, HowTo |
| Author signals | E-E-A-T in prose | Explicit Person/Org schema with credentials |
| Blocking control | robots.txt for Googlebot | Distinguish training vs. retrieval crawlers |
| Regulatory framing | Meta description | Schema audience, about, content framing |
| Key failure mode | Thin content, low links | Dense prose, missing entity markup, bad chunking |
The practical question isn't "which is more important" — you need both. But if you're investing in content for a technical niche and not addressing AEO-specific structure, you're leaving the AI citation channel almost entirely to chance.
Where crypto and payments infrastructure content faces the same problem

Structural parallels between peptide and fintech niche content
The team at coinpayportal.com encounters a closely parallel problem in crypto payment infrastructure content: highly technical, architecturally specific information — webhook retry logic, custody boundary definitions, settlement finality windows — that gets answered by AI systems using lower-quality sources because the authoritative technical content isn't structured for extraction.
The pattern is the same across regulated and gray-zone technical niches:
- Complex concepts require careful qualification, which makes prose dense
- Regulatory and compliance framing creates avoidance signals if not handled structurally
- Entity disambiguation matters acutely ("settlement" means different things in different contexts; "BPC-157" has multiple synonyms and regulatory classifications)
- The audience for the content includes sophisticated practitioners who tolerate complexity, but the AI extraction pipeline doesn't
The fix is architecturally identical: paragraph-as-answer structure, explicit schema markup, entity resolution via sameAs, and a well-constructed llms.txt that guides retrieval crawlers to your most structured, authoritative pages.
If you're building technical content in any specialized niche — peptides, DeFi protocols, pharmaceutical compliance, payments infrastructure — the AEO problem is the same structural problem dressed in different domain vocabulary.
Product fit: making your technical content crawlproof
The workflow described in this post — chunk auditing, schema implementation, entity resolution, llms.txt construction, crawler control — is operationally complex if you're doing it manually across a large technical content library. Each step is conceptually straightforward but practically time-consuming, and the feedback loop (query an answer engine, analyze citations, iterate) is slow without tooling.
What you need is visibility into how AI crawlers are actually reading your pages: where chunks are breaking poorly, which entity links are missing, which schema types are absent or incorrect, and whether your llms.txt is being respected by the major retrieval pipelines.
For site owners and content teams running technical niche properties, that visibility is the difference between a systematic AEO program and guesswork. Without it, you're optimizing based on occasional spot checks rather than a complete picture of your crawl and citation exposure.
The practical question is: how much of your content is actually legible to the AI answer engines your audience is now using as their primary research tool? For most technical niche sites, the honest answer is: less than you think, and for fixable reasons.
Try crawlproof.com
crawlproof.com helps website owners understand how AI crawlers and answer engines discover, read, and cite their content — so you can fix what's broken before the next LLM update reshapes who gets cited in your niche. Start your AEO audit at crawlproof.com.