
Pi AI is the kind of product that makes website owners uncomfortable because it does not behave like a normal search result page. A user asks a question, gets a synthesized answer, and may never see the familiar list of blue links your SEO team spent years optimizing for.
Teams think the problem is ranking for pi ai. The real problem is being understandable, retrievable, and citeable inside conversational answer workflows where the interface is only the last mile.
That changes the conversation. You are not just writing pages anymore. You are designing an information system that AI assistants can crawl, parse, trust, summarize, and reference without losing the point of your business.
The practical question is not whether Pi AI will send you the same referral traffic as Google. It probably will not. The practical question is whether your site gives answer engines enough clean evidence to include your brand when users ask high-intent questions in 2026.
Table of contents
- Pi AI is an architecture problem, not a keyword trick
- How Pi AI changes the AEO workflow
- Crawl access is the first control point
- Content structure determines whether Pi AI can use you
- Schema and metadata make your content machine readable
- llms.txt and AI files are routing hints, not magic
- Pi AI visibility depends on trust and source quality
- Build an AEO workflow for Pi AI
- What breaks when teams implement Pi AI optimization badly
- Operational checklist for pi ai visibility
Pi AI is an architecture problem, not a keyword trick

The interface hides the retrieval layer
Pi AI feels conversational, but for site owners the important part is underneath the chat. An assistant has to decide what it knows, what it should retrieve, which sources it can trust, and how much source detail to expose to the user.
That means your content is competing inside a retrieval and synthesis pipeline, not only inside a search engine results page. The mistake teams make is treating the assistant as a new display surface for old SEO tactics. They ask how to rank in Pi AI before they ask whether Pi AI, or any adjacent answer engine, can even understand the page.
A useful way to think about it is this: your website is now an API for human readers and machine readers. Humans tolerate layout quirks, hidden tabs, clever copy, and brand metaphors. Crawlers and retrieval systems need stable text, clear entities, structured context, and crawlable proof.
Why traditional SEO checklists miss the issue
Traditional SEO is still useful. Titles, headings, internal links, technical health, and content quality still matter. But AEO adds another layer: can an answer engine confidently extract a direct answer and attribute it to the right source?
If your best product explanation is locked inside JavaScript, your pricing caveats are in images, your author credentials are disconnected from the article, and your robots file sends mixed signals to AI crawlers, you do not have a pi ai visibility problem. You have an information architecture problem.
For the broader distinction, CrawlProof has a plain-language primer on what AEO is and why it is not just SEO. The short version is that SEO optimizes for discovery and ranking, while AEO also optimizes for extraction, synthesis, and citation.
What citeable really means
Citeable content is not just good content. It is content that can survive compression.
When an assistant summarizes your page, it may retain only a few claims. If those claims are vague, unsupported, or indistinguishable from every competitor, you become generic source material. If the claims are specific, verifiable, and placed next to context, your site has a better chance of being used as evidence.
Practical rule: Write every important page as if an answer engine will quote one paragraph and ignore the rest. Make that paragraph accurate, attributable, and useful on its own.
How Pi AI changes the AEO workflow
From ranking pages to supplying evidence
Pi AI pushes teams from keyword targeting toward evidence design. Instead of asking only which keywords have volume, ask which user questions your organization is qualified to answer and what proof the assistant can find on your site.
That proof may include product documentation, comparison pages, original research, pricing explanations, support policies, expert bios, changelogs, schema markup, and clear editorial dates. None of that is exciting in a hype-cycle sense. It is operational plumbing. But it is the plumbing that makes answer inclusion possible.
Related reading from our network: product teams face a similar shift from feature pages to machine-readable product evidence in answer engine optimization product management.
The answer engine pipeline
Most site owners do not need to know every internal model detail. They do need a working mental model:
- A crawler or fetcher discovers your URL.
- The system extracts text, metadata, links, and structured data.
- Content is indexed, embedded, summarized, or otherwise stored.
- A user asks a question.
- The system retrieves candidate sources.
- The assistant synthesizes an answer.
- The interface may cite, mention, or silently use sources.
What breaks in practice is usually one of the middle steps. The page exists, but the assistant cannot fetch it. The content is fetched, but the useful answer is buried in a component. The answer is visible, but the entity relationship is unclear. The claim is clear, but there is no trust signal attached.
Where your site can fall out
Here is the uncomfortable part: a site can pass basic SEO checks and still be weak for AEO.
| Layer | Traditional SEO question | AEO question for Pi AI | Common failure |
|---|---|---|---|
| Discovery | Can search engines find the URL? | Can AI crawlers and answer systems access it? | Robots rules block AI bots |
| Rendering | Does the page load for users? | Is the main answer available in raw or rendered text? | Key content hidden in scripts |
| Meaning | Does the page target a keyword? | Does the page define entities and relationships clearly? | Ambiguous brand and topic context |
| Trust | Does the page look polished? | Can the system verify authorship, dates, claims, and sources? | No crawlable proof or credentials |
| Maintenance | Is the page published? | Is the answer still current and internally consistent? | Stale pages conflict with newer content |
This is why pi ai optimization belongs in the operating model, not in a one-time content sprint.
Crawl access is the first control point
Robots rules are now business rules
Robots.txt used to feel like a technical hygiene file. In 2026, it is closer to a business policy file. It can decide whether specific classes of AI crawlers are allowed to access your public content.
Some teams block every AI bot by default because legal or leadership pressure says AI usage is risky. Others allow everything because they want visibility. Both positions can be valid depending on the business. The mistake teams make is having no explicit policy and discovering later that their implementation contradicts their strategy.
Practical rule: Do not let your robots.txt file accidentally decide your AI distribution strategy. Decide the policy first, then encode it.
AI crawler allowlists and blocks
You should know which crawlers you permit, which you block, and why. That does not mean every site should open the gates to every bot. It means the rules should be intentional.
A simplified robots.txt pattern might look like this:
User-agent: GPTBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /checkout/
This is not a universal recommendation. It is an example of expressing policy directly. Your legal, security, and marketing teams may require different rules. The point is to avoid silent contradictions.
Related reading from our network: security teams are starting to treat AI crawler exposure as part of attack-surface visibility, as described in this piece on answer engine optimization threat hunting.
Testing what bots can actually fetch
Checking robots.txt manually is not enough. You need to test the real fetch path. CDNs, WAF rules, geofencing, bot management tools, JavaScript rendering, and authentication leaks can all change what an AI crawler sees.
A practical test should answer:
- Does the crawler receive a 200 status code?
- Is the canonical URL stable?
- Is the main content present in the returned HTML or rendered output?
- Are schema blocks visible and valid?
- Are internal links crawlable?
- Are important pages blocked by noindex, canonical mistakes, or robots rules?
If you cannot answer those questions, you are guessing about pi ai visibility.
Content structure determines whether Pi AI can use you
Answerable pages beat clever pages
Brand voice matters to humans. But answer engines need clear units of meaning. The page should make it obvious what question it answers, who the answer applies to, what conditions change the answer, and what action the reader should take next.
A page about enterprise pricing, for example, should not spend 900 words circling the idea that pricing is flexible. It should explain pricing factors, contract variables, implementation costs, support tiers, and procurement timelines in clear sections.
What works:
- Short explanatory introductions.
- Descriptive H2 and H3 headings.
- Tables for comparisons and criteria.
- Definitions placed near first use.
- Explicit caveats where the answer depends on context.
What fails:
- Purely aspirational copy.
- Long pages with no direct answer blocks.
- Important claims hidden in carousels or images.
- Multiple pages giving different answers to the same question.
Entity clarity matters more than word count
Many teams still ask how long an article should be. For pi ai and other answer engines, the better question is whether the entities are clear.
If your company, product, category, audience, geography, pricing model, and use cases are not stated plainly, an assistant has to infer them. Inference introduces drift. Drift turns your specific positioning into a generic summary.
Make entity relationships obvious:
- Company X builds Product Y.
- Product Y serves Audience Z.
- Product Y is used for Use Case A and Use Case B.
- Product Y integrates with Systems C and D.
- Product Y is not designed for Scenario E.
That last line matters. Negative positioning helps answer engines avoid recommending you for the wrong query.
Put claims near evidence
Do not separate claims from proof. If you say your platform supports a standard, link or reference the documentation on the same page. If you say your team has expertise, make author or reviewer details crawlable. If you publish benchmarks, explain methodology nearby.
Practical rule: Every strong claim should have nearby evidence. If the evidence lives three clicks away, an answer engine may not connect it.
This is especially important for YMYL-like topics, regulated industries, financial services, health, security, and technical advice. Even outside those categories, assistants have incentives to prefer sources that reduce ambiguity.
Schema and metadata make your content machine readable
Use schema to reduce ambiguity
Schema markup will not rescue weak content, but it can reduce interpretation errors. For answer engines, structured data helps clarify page type, organization identity, authorship, FAQs, products, breadcrumbs, reviews, and publication dates.
A useful baseline for many sites includes:
- Organization schema on the site or about page.
- WebSite schema with search action where appropriate.
- Article or BlogPosting schema for editorial content.
- Product or SoftwareApplication schema for product pages.
- FAQPage schema when the page genuinely contains FAQs.
- BreadcrumbList schema for hierarchy.
The point is not to mark up everything. The point is to mark up the entities that remove doubt.
Keep metadata aligned with page reality
Metadata drift is common. The title says one thing, the H1 says another, the schema says the page was modified two years ago, the visible content says updated this month, and the canonical points somewhere else.
That inconsistency is not a minor technical issue. It weakens machine confidence. If an assistant has to choose between several conflicting signals, your page becomes harder to use.
Keep these aligned:
| Signal | Should match | Why it matters |
|---|---|---|
| Title tag | Primary page topic | Sets retrieval and snippet expectations |
| Meta description | Visible page promise | Reduces mismatch between summary and content |
| H1 | Main user question or topic | Anchors extraction |
| Schema type | Actual page format | Prevents wrong classification |
| Date fields | Real publish and modified dates | Supports freshness decisions |
| Canonical | Preferred source URL | Avoids duplicate-source confusion |
Do not outsource meaning to markup
Some teams treat schema like a cheat code. They add FAQ schema to thin answers, Product schema to vague landing pages, and Article schema to content with no byline, date, or substance.
That fails because markup is a hint, not reality. If the visible page does not support the structured data, you have created another inconsistency. AEO rewards clarity; it does not reward decoration.
The practical implementation pattern is simple: write the page so a knowledgeable human can understand it, then add schema so a machine can confirm it.
llms.txt and AI files are routing hints, not magic
What these files can help with
Emerging files like llms.txt and related AI-facing documents are attempts to give crawlers a cleaner map of important content. They can point answer engines toward canonical docs, summaries, policies, or high-value pages.
For a site owner, these files are useful because they force prioritization. What do you actually want an AI system to read first? Your homepage? Your documentation? Your product comparison page? Your pricing policy? Your editorial archive?
CrawlProof has a deeper explanation of llms.txt and skill.md for teams that want the practical file-level implementation details.
What they cannot fix
An llms.txt file cannot compensate for blocked crawlers, weak content, broken canonical tags, inaccurate schema, or contradictory pages. It is a routing hint. It is not an indexing contract.
The mistake teams make is publishing the file and assuming they are now optimized for Pi AI. That is like adding a sitemap while the actual pages return 403s or contain no useful content.
Use AI files to guide discovery, not to hide architectural debt.
A minimal implementation pattern
A minimal pattern looks like this:
- List your most authoritative pages by topic.
- Prefer stable canonical URLs over campaign URLs.
- Include short descriptions that explain why each page matters.
- Exclude thin, outdated, duplicate, or low-trust pages.
- Review the file whenever your positioning or documentation changes.
A simple conceptual entry might look like:
# Product overview
https://example.com/product
Primary explanation of the product, audience, use cases, and limitations.
# Pricing policy
https://example.com/pricing
Current pricing model, plan differences, billing rules, and contract notes.
The file should reflect your real content hierarchy. If it becomes a dumping ground, it loses value.
Pi AI visibility depends on trust and source quality
Trust signals need to be crawlable
Trust signals are not only badges on a page. They are facts that machines can access and connect. Author names, reviewer names, company details, editorial policies, contact information, support pages, documentation, and update history all matter more when answer engines decide which sources to use.
If those signals are hidden behind modals, embedded as images, or scattered across disconnected pages, they are weaker. Make them crawlable and internally linked.
For example, an article about AI crawler behavior should connect to the author or organization behind it, show a modified date, define the scope of the advice, and link to relevant supporting documentation. That does not guarantee citation, but it reduces uncertainty.
Freshness is operational, not cosmetic
Changing a visible date without updating the substance is a bad habit. Answer engines may use freshness signals, but freshness without content accuracy is fragile.
A better workflow is to maintain pages with explicit review cycles:
- Product pages reviewed after major releases.
- Comparison pages reviewed when competitors change pricing or features.
- Technical guides reviewed when standards, crawler behavior, or APIs change.
- Policy pages reviewed when legal or platform requirements change.
In AEO, stale content creates two risks. First, the assistant may ignore it. Second, worse, it may use it and produce an outdated answer associated with your brand.
Conflicting content weakens citation confidence
Many sites have five versions of the same answer: a blog post, an old help doc, a sales deck landing page, a comparison page, and a changelog note. Humans can sometimes reconcile them. Machines often cannot.
Create a source-of-truth model. Decide which page owns each durable answer. Other pages can reference it, summarize it, or add context, but they should not contradict it.
Practical rule: If two pages answer the same commercial question differently, pick an owner. Answer engines do not owe you the most convenient interpretation.
Related reading from our network: even in unrelated technical markets, the same operational problem appears when state, trust, and reconciliation are not treated as first-class architecture, as shown in this guide to payment gateway architecture.
Build an AEO workflow for Pi AI
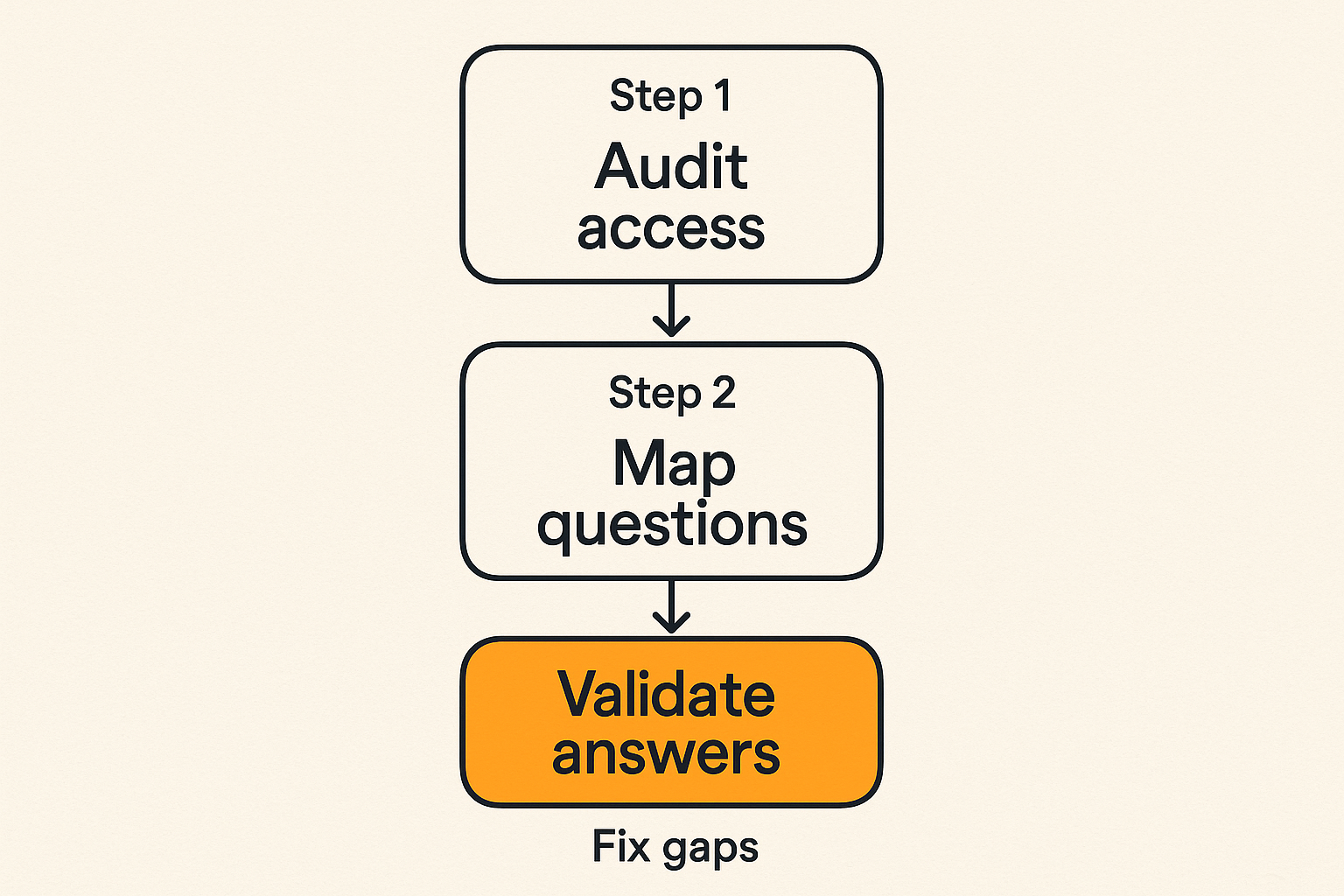
Step 1 audit crawlability
Start with access. Before rewriting pages, confirm that AI-oriented crawlers and general fetchers can reach the pages you care about.
A useful audit sequence:
- Select priority URLs by business value, not traffic alone.
- Check robots.txt rules for AI and general crawlers.
- Test HTTP status, redirects, canonical tags, and noindex directives.
- Render the page as a crawler would and compare it with the user view.
- Validate schema and metadata alignment.
- Record blockers and assign owners.
This is where teams often find boring but expensive issues: a CDN challenge blocks non-browser requests, product copy is client-rendered but not available in initial HTML, or a canonical points to a thin variant of the page.
Step 2 map questions to evidence pages
Next, map the questions you want to be associated with to evidence pages that can answer them.
Do not start with a giant keyword export. Start with business questions:
- What are we?
- Who are we for?
- What problem do we solve?
- How are we different?
- What do we integrate with?
- What does it cost?
- What are the limitations?
- What should a buyer compare us against?
For each question, identify the canonical page that answers it. If no page exists, create one. If multiple pages answer it inconsistently, consolidate or clarify ownership.
Step 3 validate outputs and fix gaps
Finally, test how answer engines respond. You cannot control every output, and you should not pretend that a single prompt is a definitive benchmark. But repeated testing across realistic questions can reveal gaps.
Look for patterns:
- Your brand is omitted from category answers.
- Your brand is mentioned but described incorrectly.
- Competitors are cited for claims you cover better.
- Old pages influence current answers.
- AI systems describe your product too generically.
- The assistant cannot identify your target audience or limitations.
Those patterns become backlog items. Some are content fixes. Some are schema fixes. Some are crawl access fixes. Some are positioning fixes.
What breaks when teams implement Pi AI optimization badly
Blocking the bots you want to influence
The most obvious failure is also one of the most common: marketing wants visibility, legal wants restrictions, engineering ships a broad block, and nobody reconciles the policy.
The result is a site that publicly wants to be included in AI answers while technically denying access to the crawlers that might support that outcome. This is not a content problem. It is ownership failure.
A practical governance model assigns one owner for AI crawler policy, one owner for technical enforcement, and one owner for business impact. Without that triangle, changes happen in silos.
Publishing answer fragments without authority
Another failure mode is mass-producing question-and-answer pages with no authority behind them. These pages may look optimized because they match prompts, but they do not provide differentiated evidence.
Answer engines do not need another generic page defining a common term. They need a source that contributes something reliable: original data, expert interpretation, product-specific detail, operational guidance, or clear documentation.
If your content strategy is only to mimic the questions users ask, you will build a library of fragments. If your strategy is to answer the questions your organization is uniquely qualified to answer, you build citation assets.
Measuring only traffic and missing influence
Pi AI and other assistants may not always send clean referral traffic. Users may get answers without clicking. That makes old measurement models incomplete.
Traffic still matters, but it is not the whole system. Track influence signals too:
- Is your brand mentioned in relevant AI answers?
- Are descriptions accurate?
- Are competitors cited where you should be eligible?
- Are important pages crawlable by AI bots?
- Are answer pages internally consistent?
- Are support and sales teams hearing AI-generated misconceptions?
The practical question is not whether AEO replaces SEO reporting. It does not. The question is whether your reporting can see when answer engines shape demand before a click happens.
Operational checklist for pi ai visibility
Run these checks before publishing
Before a page becomes part of your AEO program, run a basic readiness check:
- The page answers a specific user or buyer question.
- The main answer is visible in crawlable text.
- The title, H1, schema, and canonical agree.
- Claims are supported near the claim.
- Authors, organization details, or review signals are accessible.
- Internal links connect the page to related source-of-truth pages.
- Robots and meta directives do not block intended access.
- The page is included in any relevant AI-facing routing file.
This is not bureaucratic overhead. It is how you prevent the same mistakes from being repeated across every content launch.
Assign ownership after launch
AEO breaks when nobody owns the lifecycle. Content teams publish, developers change templates, legal updates bot policy, product changes positioning, and analytics teams keep reporting only organic sessions.
Assign owners for:
| Workstream | Owner type | Review trigger |
|---|---|---|
| AI crawler policy | Technical or platform owner | Bot policy, CDN, WAF, robots changes |
| Content accuracy | Editorial or product marketing owner | Product, pricing, positioning changes |
| Schema and metadata | SEO or web owner | Template changes, new content types |
| Answer testing | AEO or growth owner | Quarterly checks, launches, market changes |
| Feedback loop | Sales, support, marketing ops | Incorrect AI-generated buyer assumptions |
Ownership turns AEO from a one-off audit into a repeatable workflow.
Use crawl data to close the loop
This is where CrawlProof fits. Site owners need to see what AI crawlers and answer engines can actually find, not what the CMS preview suggests should be visible. CrawlProof is built as an AEO auditor for that exact operational gap: crawl access, content visibility, schema, robots rules, AI-bot access, and positioning.
You can use CrawlProof to run an audit on a priority URL and compare the machine-visible version against your intended answer architecture. The public CrawlProof blog also covers the practical edge cases around AEO, LLM crawlers, schema markup, and AI citation behavior as the standards evolve.
The goal is not to chase every assistant with a separate playbook. The goal is to build a website that is technically accessible, semantically clear, and trustworthy enough to be used by answer systems. If Pi AI is part of your audience path, the same discipline applies: clean access, clear evidence, structured meaning, and ongoing validation.
In closing, pi ai optimization is not a prompt hack. It is the work of making your public knowledge base understandable to machines and useful to humans at the same time.
Try crawlproof.com
CrawlProof helps site owners and marketers understand how AI answer engines and LLM crawlers discover, parse, and cite their content. Try crawlproof.com.