
The security industry has a content problem that most teams have not named yet. Vendors publish detailed threat reports, researchers write thorough blog posts about detection logic, and product teams document integrations carefully. Then a buyer asks an AI assistant which threat intelligence platform to evaluate — and the answer comes back citing three vendors the security team had never prioritized for SEO.
That is not a brand awareness failure. It is an architecture failure. The content exists, but it was never structured for the way AI answer engines consume and cite sources.
Teams think the problem is producing more content. The real problem is that AI answer engines — ChatGPT, Perplexity, Gemini, Claude with web access, and the growing class of LLM-powered search surfaces — do not retrieve and rank content the way Google does. They ingest, compress, and synthesize. If your content is not structured to survive that compression, it disappears from the answer entirely, even if it would have ranked on page one a few years ago.
This post is about the architectural decisions that determine whether a threat intelligence brand gets cited by AI answer engines or gets left out of the answer altogether. It is written for security marketers, content strategists, and technical teams who understand threat intel but are new to optimizing for AI indexing.
Table of contents
- Why threat intelligence content fails in AI answer engines
- Reframing AEO as a content architecture decision
- How AI answer engines evaluate threat intelligence sources
- Schema markup for threat intelligence content
- The llms.txt standard and what it means for security sites
- Content types that earn citations in threat intelligence AEO
- Common failure modes in threat intelligence AEO
- What breaks when you optimize for AI but ignore crawl infrastructure
- Implementation sequence for threat intelligence AEO
- Measuring citation performance
- Where crawlproof.com fits in this workflow
Why threat intelligence content fails in AI answer engines

The compression problem
When a large language model ingests a piece of content, it does not store the page. It compresses meaning. Paragraphs that take 800 words to make one point get reduced to a token-level representation of that point. The elaborate context you used to establish authority in traditional SEO — the long-form preamble, the methodology section, the nuanced caveats — mostly evaporates.
Security content is especially vulnerable here. Threat intelligence reports are written for practitioners. They are dense, conditional, filled with technical qualifiers. That density serves a defensive analysis use case well. It serves an AI answer engine poorly, because the compression process tends to favor content that makes clean, extractable claims over content that hedges every assertion.
A useful way to think about it is this: every paragraph in your content should be able to stand alone as an answer to a specific question. If it cannot, it probably does not survive into the model's working representation of your site.
What LLM crawlers actually look for
LLM crawlers — GPTBot, ClaudeBot, PerplexityBot, and others — behave differently from Googlebot. They are less interested in PageRank-style link graphs and more interested in semantic coherence and extractability. A few signals that matter:
- Clear question-answer structure: Headers that are phrased as questions or strong declarative statements outperform vague section titles.
- Consistent terminology: Security content that uses five different terms for the same concept ("IOC", "indicator", "observable", "artifact", "signal") confuses entity resolution. Pick a primary term and define variants explicitly.
- Low boilerplate ratio: Pages stuffed with navigation, disclaimers, and repeated footer content get lower signal-to-noise scores. Keep the ratio of substantive content to boilerplate high.
- Accessible rendering: If the page requires JavaScript to render its main content, many LLM crawlers will see a shell. More on this in a later section.
Practical rule: Write every H2 heading as if it were the exact question a buyer types into Perplexity. If you would not search for that phrase, the heading is probably decorative rather than extractable.
Reframing AEO as a content architecture decision
Atomic answers versus narrative prose
The mistake teams make is treating AEO as a layer on top of existing content — add some FAQ schema, tweak a few headings, done. The real work is upstream: restructuring how information is organized so that individual units of content can be extracted and cited without the surrounding context.
Call these "atomic answers": discrete chunks of content that answer one specific question completely, without requiring the reader (or the model) to have read the preceding three sections. In threat intelligence content, this means:
- A definition of a technical term should appear in the section where it is first used, not just in a glossary at the end.
- A comparison between two detection approaches should include a summary statement that encapsulates the comparison, even if the body goes deeper.
- A process description should include a numbered sequence that stands alone, separate from the prose explanation.
This is not dumbing content down. It is recognizing that your content will be consumed in fragments by systems that do not read linearly.
The entity graph problem for security brands
AI answer engines build entity graphs — mental maps of which organizations, concepts, and topics are related. For a threat intelligence vendor, the goal is to be strongly associated with the specific entities that buyers query: threat actor names, malware families, detection frameworks like MITRE ATT&CK, and use cases like SOC automation or vulnerability prioritization.
The problem is that many security brands publish content that is adjacent to these entities without explicitly claiming association. They write about ransomware without naming their product's specific capability against it. They discuss MITRE ATT&CK techniques without mapping those techniques to their own detection logic.
That changes the conversation. Instead of asking "how do we rank for threat intelligence?", the question becomes "which specific entities are we authoritatively associated with, and does our content structure make those associations explicit enough for a model to extract them?"
Practical rule: For every major threat actor, malware family, or framework your product addresses, publish at least one page that explicitly names the entity in the H1, defines it in the first paragraph, and connects it to your product or methodology by name in the body.
How AI answer engines evaluate threat intelligence sources
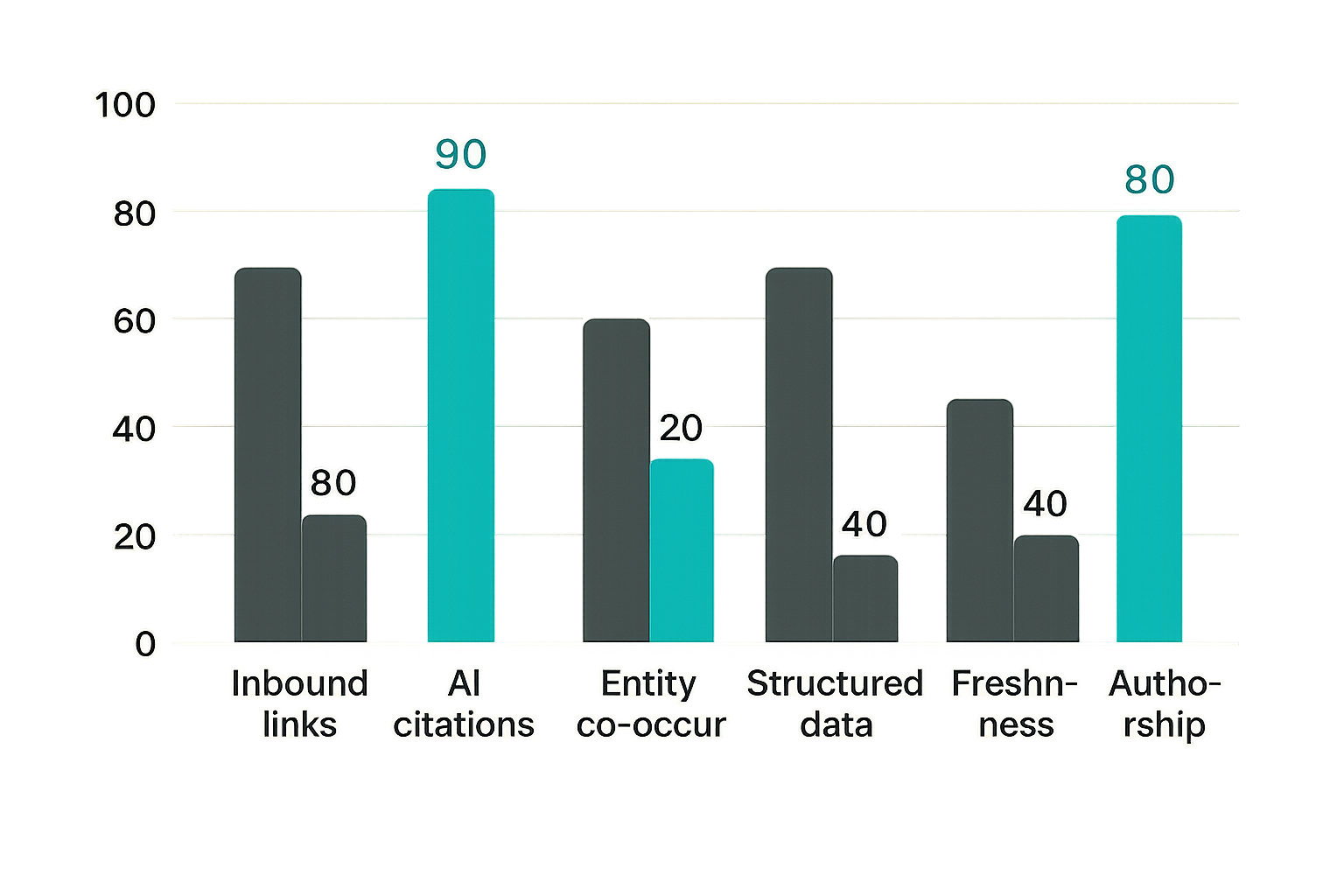
Authority signals that survive compression
Traditional domain authority — the accumulated weight of inbound links — still matters, but it is not sufficient for AEO. AI answer engines layer additional signals on top of link-based authority:
| Signal | Traditional SEO weight | AEO weight | Notes |
|---|---|---|---|
| Inbound links from authoritative domains | High | Medium | Still matters, but less deterministic |
| Direct citations in other AI-indexed content | Low | High | Content cited by other cited sources compounds |
| Entity co-occurrence with known authorities | Low | High | Being mentioned alongside CISA, NIST, MITRE helps |
| Structured data completeness | Medium | High | Schema enables confident entity resolution |
| Content freshness on evergreen topics | Low | Medium | Models downweight stale definitions |
| Explicit authorship and credentials | Low | High | E-E-A-T signals survive into model training |
The insight here is that security brands with strong practitioner reputations but weak traditional SEO footprints can close the gap faster in AEO than in traditional search — if they structure their content correctly. The team at threatcrush.com has observed this pattern repeatedly: organizations with genuinely authoritative threat research getting outcompeted in AI-generated answers by vendors who understand content architecture better.
Why freshness matters differently in threat intel
In traditional SEO, freshness is a ranking factor mostly for news-adjacent queries. In threat intelligence AEO, freshness has a more nuanced role. AI models are trained on data with cutoff dates, but retrieval-augmented systems (like Perplexity with live web access) weight recent content more heavily for queries about active threats.
This creates a two-tier freshness requirement:
- Evergreen definitional content ("What is a threat actor?", "How does SIEM differ from SOAR?") should be updated incrementally to reflect current terminology and product capabilities, not rewritten from scratch each cycle.
- Tactical threat content (specific CVEs, active campaigns, current actor TTPs) should be published fast and tagged with explicit dates. Models use publication dates as a trust signal for time-sensitive claims.
What breaks in practice is when security teams treat all content as either evergreen or tactical without a clear classification. Evergreen pages get stale. Tactical pages get orphaned after the immediate news cycle passes. Neither type gets maintained in a way that serves AI indexing.
Schema markup for threat intelligence content
Which schema types actually move the needle
Schema markup is one of the cleaner signals you can give an AI answer engine because it is explicit machine-readable metadata. For threat intelligence content specifically, these schema types are most valuable:
Article/TechArticle: Sets publication date, author, and organization. For security content, always useTechArticlewhen the content is technical — it carries stronger E-E-A-T signals.FAQPage: Wraps individual question-answer pairs. Directly maps to the atomic answer structure described earlier. High extraction value.HowTo: For process content (incident response workflows, detection tuning guides). Step-level granularity helps models extract procedural answers.Organization(on your homepage and About page): Establishes your brand as an entity with asameAsproperty linking to Wikidata, LinkedIn, Crunchbase, and other authority nodes.SoftwareApplication(for product pages): Maps your product to specific use cases and categories that models use to answer "which tool should I use for X" queries.
The mistake teams make is adding schema to a handful of pages and calling it done. Schema coverage needs to be systematic — every content type mapped to the right schema, every page publishing its metadata consistently.
Structured data pitfalls in security content
A few failure modes specific to this space:
- Overly broad
aboutproperties: Listing 40 topics in yourArticleschema'saboutfield dilutes entity association. Be specific — three to five tightly scoped topics per piece. - Missing
authorentities: Many security blogs publish under a company byline without a structuredPersonentity. This weakens E-E-A-T signals significantly. - Stale
dateModified: If you update a page but do not updatedateModifiedin the schema, models may weight the original publication date. Automate this. - Schema on JavaScript-rendered pages: If your schema is injected client-side and a crawler never executes JavaScript, your structured data is invisible. Render schema server-side.
Practical rule: Audit your three highest-traffic pages for schema completeness before touching anything else. Get those right as a template, then systematize across the content inventory.
The llms.txt standard and what it means for security sites
What belongs in your llms.txt
llms.txt is an emerging convention — a plain-text file at the root of your domain that explicitly signals to LLM crawlers which content is authoritative, how it is organized, and what the site's purpose is. Think of it as robots.txt combined with a site map, but written in natural language for model consumption rather than for Googlebot.
For a threat intelligence brand, a well-structured llms.txt should include:
- A one-paragraph description of what the organization does and what its content covers.
- An explicit list of the primary topics the site addresses, using canonical terminology ("threat actor tracking", "malware analysis", "detection engineering") rather than marketing language.
- Links to key reference pages — your product overview, your methodology documentation, your most authoritative threat reports.
- An explicit statement of authorship credentials — who publishes this content and what qualifies them.
The practical question is not whether llms.txt is a confirmed ranking factor yet. It is whether being an early adopter of a signal that is clearly directionally aligned with how models want to consume web content creates compounding advantage. The answer is yes.
What security teams get wrong about llms.txt
The most common mistake is treating llms.txt as a marketing document — filling it with brand language, product claims, and vague capability statements. Models do not respond to that. They respond to precise, entity-rich descriptions that map cleanly to their internal representation of the topic domain.
A second common error is creating llms.txt and then not maintaining it. If the file describes content that no longer exists, or omits major new sections of the site, it actively misleads crawlers. Assign ownership of llms.txt maintenance to whoever owns your content calendar.
Content types that earn citations in threat intelligence AEO

Definitional and reference content
Definitional content — "What is X?" pages for every major concept in your domain — is the highest-ROI investment in threat intelligence AEO. These pages serve as the canonical reference that models pull from when answering foundational queries. If your definition of "threat intelligence" or "attack surface management" is the clearest, most current, most entity-rich version indexed, you earn the citation.
The standard for a strong definitional page in 2026:
- H1 is the term being defined, phrased naturally ("What Is Threat Intelligence?" or "Threat Intelligence: A Technical Definition").
- First paragraph contains a clean, complete definition in two to three sentences — no preamble.
- Body expands with subtypes, related concepts, and use cases, each in its own subsection.
FAQPageschema wraps the most common questions about the term.- Internal links connect to related definitional pages (building your own entity graph).
Comparison and evaluation content
When buyers query AI answer engines about tool selection — "What is the difference between a TIP and a SIEM?" or "Which threat intelligence platforms integrate with Splunk?" — the models tend to cite sources that have explicit, structured comparison content rather than sources that make vague superiority claims.
A useful comparison page structure:
- Clear title naming both things being compared.
- A summary table (the kind that survives compression — short cells, clear column headers).
- A "When to use X" and "When to use Y" section that gives decision criteria, not just descriptions.
- Explicit neutral language — models are trained to be skeptical of promotional framing and downweight obvious vendor self-promotion.
Process and workflow content
How-to content and workflow documentation are underused citation magnets in security marketing. When someone asks Perplexity "how do I build a threat intelligence program?", the answer will pull from sources that have clear, numbered, step-by-step content — not from sources that describe the process in flowing prose.
Every major process your product supports or your team has expertise in should have a dedicated page with an explicit numbered sequence, a HowTo schema wrapper, and each step described with enough specificity that it stands alone.
Common failure modes in threat intelligence AEO
The gated content trap
This is the most damaging structural problem in security content marketing. The best research — the annual threat reports, the detailed actor profiles, the in-depth vulnerability analyses — gets gated behind lead capture forms. AI crawlers cannot access gated content. It contributes nothing to your AEO footprint.
The practical question is not whether to gate content at all. It is which content gets gated and which does not. A reasonable framework:
- Gate: raw data exports, tool access, personalized assessments, lengthy reports that require human analyst time to produce.
- Do not gate: definitional content, methodology overviews, summary findings that establish your authority on a topic, anything you want cited by AI answer engines.
Many teams gate everything that took effort to produce, reasoning that effort implies value implies gating. That logic fails in AEO. Effort that AI crawlers cannot see produces zero citation authority.
Jargon density without definitions
Security content is dense with acronyms: TTP, IOC, APT, SIEM, SOAR, EDR, XDR, MTTD, MTTR. This density is appropriate for a practitioner audience reading linearly. It is a problem for AI answer engines that need to resolve entities confidently.
The fix is not to remove jargon — it is to define it on first use and ensure that your definitions are internally consistent. Use the DefinedTerm schema type for key terms when they appear in your content. Make sure your glossary pages (if you have them) are crawlable, schema-marked, and internally linked from the pages that use those terms.
Publishing cadence mismatches
Models that use retrieval augmentation (live web access) develop implicit expectations about how often authoritative sources update. A site that published three substantial pieces of threat intelligence content per week for two years and then went quiet for six months will see its citation rate fall — not because its existing content degraded, but because recency signals weaken.
This does not mean publishing for its own sake. It means that if your team produces threat intelligence at a certain cadence internally, a portion of that work should be structured for public indexing rather than staying in internal wikis and customer portals.
What breaks when you optimize for AI but ignore crawl infrastructure
JavaScript-rendered pages and LLM crawlers
Many modern security product sites are built on React, Next.js, or similar frameworks. In best-case configurations, these frameworks server-side render content so crawlers see the full page. In practice, many implementations serve a JavaScript shell to non-browser clients, meaning LLM crawlers see almost nothing.
To verify your rendering status: fetch your pages with a raw HTTP client (curl or a headless request without JavaScript execution) and compare what you see to what a browser renders. If the content differs substantially, your LLM crawl coverage is likely poor regardless of how good your content strategy is.
Specific things that commonly break:
- Product feature descriptions loaded via client-side API calls.
- Blog posts that require JavaScript for the article body to render.
- Schema markup injected via
useEffecthooks that never run in a crawler context.
Inconsistent canonical signals
Security sites often accumulate content across subdomains: blog.example.com, docs.example.com, research.example.com. Each subdomain is treated as a separate entity by most crawlers. This dilutes domain authority and creates confusing entity signals — the model cannot tell whether these are one organization or several.
The recommendation is not necessarily to collapse everything to one domain, but to ensure that canonical relationships are explicit, that cross-subdomain linking is consistent, and that your Organization schema uses sameAs to unify these properties under one entity.
Implementation sequence for threat intelligence AEO
Auditing your existing content inventory
Before creating new content, audit what you have. The goal is to identify which pages have citation potential and what is blocking them from being extracted effectively.
- Crawl your site for rendering issues — identify pages where a headless HTTP request returns substantially less content than a browser renders.
- Map content to query types — for each page, identify the specific question it answers. If you cannot identify a question, the page probably needs restructuring.
- Check schema coverage — which content types have structured data? Which are missing it?
- Assess gating — which high-value content is behind forms? Map the cost of ungating against the citation authority upside.
- Review
llms.txt— does it exist? Is it current? Does it accurately represent your authoritative content? - Identify entity gaps — which threat actors, malware families, or frameworks should you be associated with but currently have no explicit content covering?
Prioritizing pages by citation potential
Not all pages are equal for AEO. Once you have your audit, prioritize remediation in this order:
- Homepage and About page: Entity establishment. Get
Organizationschema right here first. - Top definitional pages: Highest query volume, highest citation leverage.
- Product pages: These answer "what tool should I use" queries.
SoftwareApplicationschema, comparison tables, use-case specificity. - Methodology and research pages: Authority signals. Ungating if currently gated.
- Blog posts with process content: Add
HowToschema, restructure for atomic answers. - Tactical threat reports: Ensure date metadata is accurate, publication cadence is maintained.
Measuring citation performance
Proxy metrics when direct data is unavailable
Direct visibility into AI answer engine citation rates is limited — most platforms do not publish referral data in a way that cleanly separates AI-generated answer traffic from other sources. In the interim, practical proxy metrics include:
| Metric | What it signals | How to track |
|---|---|---|
| Direct traffic trend | Brand awareness and unprompted recall | GA4 / analytics |
| Branded search query volume | Whether AI mentions drive searches | Google Search Console |
| Referral traffic from Perplexity, Bing AI | Confirmed AI-assisted citations | Analytics referrer data |
| LLM crawler activity in server logs | Which models are crawling you and how often | Server log analysis |
| Mention velocity in third-party content | Whether your brand appears in content others publish | Alerting tools |
The mistake teams make is waiting for perfect measurement before investing in AEO. The window for establishing citation authority on foundational security topics is not unlimited. Early movers in threat intelligence AEO are building entity associations that will be harder for late entrants to displace.
Where crawlproof.com fits in this workflow
Most of the work described in this post — auditing rendering, validating schema, testing LLM crawler behavior, understanding how AI indexing treats your content — requires infrastructure that traditional SEO tooling was not built to provide. Google Search Console tells you how Googlebot sees your site. It tells you nothing about how GPTBot or ClaudeBot processes your content, whether your llms.txt is effective, or whether your schema is surfacing correctly in AI answer contexts.
This is the gap that crawlproof.com addresses. For security brands specifically, the combination of strong practitioner expertise with weak AI-indexing infrastructure is the most common pattern we observe. The expertise deserves to be cited. Getting there requires understanding exactly what AI crawlers see when they visit your site — not what your analytics dashboard shows, and not what a browser renders.
The implementation sequence above is sound without any tooling. It is faster and more reliable with infrastructure that can actually simulate LLM crawler behavior, validate your schema coverage, and flag the rendering gaps that are invisible to traditional audits.
Try crawlproof.com
CrawlProof helps website owners, SEO professionals, and content teams understand how AI answer engines and LLM crawlers discover, process, and cite their content — so the work you put into content actually earns the citations it deserves. Start at crawlproof.com.