Most website teams do not have a content problem. They have a topology optimization problem.
They publish good pages, add a few schema blocks, wait for AI answer engines to notice, and then wonder why competitors with thinner content get cited. The page exists. The expertise exists. The crawlable route to that expertise does not.
Teams think the problem is writing more articles. The real problem is that answer engines evaluate your site as a connected system: URLs, internal links, entity signals, schema, canonical pages, robots rules, and evidence trails.
That changes the conversation. Topology optimization for AEO is not about making a prettier sitemap. It is about shaping the structure of your website so AI crawlers can discover, classify, and trust the right content with less ambiguity.
Table of contents
Why topology optimization matters for AEO in 2026
The crawl path is now a product surface
In traditional SEO, teams often treat site structure as a ranking support system. It helps distribute authority, expose pages to crawlers, and guide users. That still matters.
But for answer engine optimization, the crawl path has become part of the product surface. An AI crawler is not only checking whether a URL exists. It is trying to infer what the page is, what claim it supports, whether the claim belongs to your brand, and how the page relates to other pages that confirm or qualify it.
A page that is technically indexable can still be operationally invisible. It may sit three template layers deep, lack descriptive inbound links, have schema that says one thing while the copy says another, and receive no reinforcement from adjacent pages.
The mistake teams make is assuming that if a page is live, answer engines will understand it. In production, discovery is not the same as comprehension.
Teams think the problem is content volume
Content volume is easy to buy. You can add fifty pages, expand a glossary, or turn every sales objection into a blog post.
What breaks in practice is that volume without topology creates noise. You get duplicated answers, unclear canonical pages, thin hub pages, and internal links that point everywhere without explaining why. AI systems do not need more loosely connected text. They need a cleaner path from question to answer to evidence.
If you are new to the shift from SEO to answer engines, the distinction is worth making explicit: Answer Engine Optimization is not just SEO with a new acronym. It changes the unit of work from ranking pages to making answers machine-discoverable and citation-ready.
The practical question is graph quality
A useful way to think about it is this: your website is a graph. Pages are nodes. Links are edges. Schema, headings, author data, navigation, and file-level crawler instructions are signals attached to the graph.
Topology optimization asks whether that graph is shaped for the outcome you want. For AEO, the outcome is simple to state and hard to execute: when an AI answer engine needs information you are qualified to provide, it should find the best URL, understand why that URL is authoritative, and have enough supporting context to cite it.
Practical rule: Do not optimize isolated pages first. Optimize the route an AI crawler takes to reach, understand, and verify those pages.
Define topology optimization for websites, not CAD software
Nodes, edges, and evidence
In engineering, topology optimization is about distributing material inside constraints to achieve a better design. For websites, the metaphor is useful if you do not overcomplicate it.
Your material is content and metadata. Your constraints are crawlability, user intent, business priorities, templates, CMS rules, and crawler policies. Your design goal is a site graph that makes important answers easy to discover and hard to misinterpret.
That means you are not merely asking, “Do we have a page for this keyword?” You are asking:
- Is there one clear answer page for this topic?
- Do supporting pages point to it with descriptive anchors?
- Does schema confirm the page type, entity, and relationship?
- Can major crawlers reach it without depending on fragile client-side behavior?
- Does the surrounding site reinforce the same entity and expertise signals?
What answer engines need
Answer engines and LLM-based retrieval systems vary, and nobody outside those teams knows every detail. But many systems need the same practical inputs: accessible content, clear page purpose, reliable entities, consistent metadata, and evidence that the page is not an isolated fragment.
The practical question is not whether you can “trick” an answer engine. You should assume that shallow tricks decay quickly. The better question is whether your website architecture makes your real expertise legible.
Here is the operator-level contrast:
| Page-by-page SEO | Individual rankings and snippets | Some pages perform, but AI crawlers may miss the broader evidence graph |
| Content volume | More URLs and keyword coverage | Duplicate or weak pages compete with each other |
| Topology optimization | Crawl paths, page roles, links, schema, and evidence | Important answers become easier to discover, classify, and cite |
| Prompt-era shortcuts | Surface-level “AI-friendly” formatting | Short-term polish without durable crawl or trust improvements |
Where traditional SEO gets it partly right
Traditional technical SEO already gives you useful tools: clean URLs, internal links, canonicals, sitemaps, structured data, status codes, robots rules, and page speed. Do not throw those away.
The difference is priority. In SEO, the site graph often serves ranking and user navigation. In AEO, the graph also serves answer extraction and source selection.
That changes how you judge a link. It is not just a path to pass authority. It is a statement: this page supports that answer, this concept belongs to that entity, and this cluster represents our expertise on this topic.
Map the current topology before you change it
Inventory pages by answer role
Before you rewrite anything, map what you already have. Most teams skip this and start redesigning navigation. That is backwards.
Create a simple inventory with one row per important URL. Add columns for:
- Primary question the page answers
- Page role: canonical answer, support evidence, comparison, glossary, product, documentation, case proof, or policy
- Target entity or topic
- Inbound internal links
- Outbound internal links
- Schema type
- Indexability and crawler access
- Last updated date
- Business owner
You are looking for mismatches. A page that should be a canonical answer may be treated like a blog archive item. A support page may be receiving more internal links than the definitive guide. A product page may make a claim that no educational page explains.
Trace bot-visible paths
Do not map only what a human can click. Map what a crawler can fetch.
For each important page, trace the shortest crawlable route from your homepage and from relevant hub pages. Then check whether the route depends on scripts, search boxes, filters, or interactions that an AI crawler may not execute reliably.
A practical audit question: if a crawler starts at your homepage, can it reach your best answer to a commercially important question in three to five meaningful clicks? “Meaningful” means links visible in HTML or reliably rendered, with anchors that describe the destination.
Related reading from our network: teams building agent-facing interfaces run into a similar state and navigation problem in interactive presentation tools as agent workflow surfaces, where the workflow matters more than the UI layer.
Compare rendered and raw access
Many website owners check the browser view and stop there. That is not enough.
Compare at least three views:
- The user-facing rendered page.
- The raw HTML fetched without running a full browser.
- The page as seen under common bot and crawler constraints.
You are looking for missing main content, hidden navigation, blocked resources, inconsistent canonical tags, and structured data that appears only after delayed JavaScript execution.
Practical rule: If your best content only appears after a fragile render path, treat it as partially unavailable to answer engines until proven otherwise.
Build answer clusters around entity ownership
Choose canonical answer pages
AEO topology optimization starts with ownership. What questions should your site be the source for?
For each owned question, choose one canonical answer page. This does not always mean the longest page. It means the page that should be cited when an answer engine needs the cleanest source.
Examples:
- “What is your product category?” may belong to a durable educational guide.
- “How does your product compare to X?” may belong to a comparison page.
- “What does your API support?” may belong to documentation.
- “What does your company believe about a standard?” may belong to a technical explainer.
Once you choose the canonical page, reduce ambiguity. Update internal links, page titles, schema, breadcrumbs, and hub pages so the site consistently points to that URL as the answer.
Use supporting pages as evidence
Supporting content should not compete with the canonical answer. It should strengthen it.
A blog post can provide a timely example. A documentation page can prove implementation detail. A case study can show applied credibility. A glossary page can define a term. Each should point back to the canonical answer where appropriate.
This is where many content programs fail. They produce supporting pages that all target the same answer. The result is internal competition and unclear citation targets.
A better pattern:
- Canonical answer page: stable, broad, citation-ready.
- Support page: narrow, specific, linked to the canonical page.
- Hub page: navigational, not pretending to be the answer itself.
- Product page: conversion-focused, backed by educational evidence.
Avoid orphan expertise
Orphan expertise is content that proves you know something but is not connected to the rest of your site graph.
It may be a strong technical article buried in an archive. It may be a PDF with no structured context. It may be a product documentation page that answers a common market question but has no path from the blog or homepage.
Answer engines can only use what they can discover and interpret. If a strong page has no inbound links from relevant nodes, no schema, no updated metadata, and no relationship to your main entity, it is not doing its full job.
Use topology optimization to fix internal linking

Link for intent transitions
Internal links should describe how a reader or crawler moves from one intent to the next.
Bad internal linking says: “Here are some related posts.”
Useful internal linking says: “If you are trying to understand the standard, go here. If you are ready to implement it, go here. If you need proof that this applies to your use case, go here.”
That changes the conversation because links become workflow markers. They tell answer engines which pages define, validate, compare, and operationalize a topic.
For AEO teams, topology optimization should prioritize these transitions:
- Definition to implementation
- Problem to solution
- Claim to evidence
- General topic to specific use case
- Educational guide to product or audit path
- Standard or protocol to your interpretation of it
Use anchors that describe the claim
Anchor text is not decoration. It is a small but important semantic signal.
Compare these links:
- “Read more”
- “Click here”
- “Learn about schema markup for answer engines”
- “See how AI crawlers handle llms.txt files”
The last two give the crawler context before it fetches the destination. You do not need to stuff exact-match keywords everywhere. You do need anchors that explain why the destination matters.
The mistake teams make is using internal links as generic navigation furniture. For AEO, every important internal link should carry a job.
Keep navigation crawlable
Modern websites often hide important routes behind menus, filters, accordions, infinite scroll, or client-side state. Some of that is fine for users. It is risky for crawlers if there is no simpler fallback.
Keep critical paths available as normal links. Put important hubs in HTML navigation. Make breadcrumbs real links. Avoid relying on search-only discovery for important pages.
A small checklist:
- Primary hubs are linked from global or section navigation.
- Canonical answer pages are linked from hubs and supporting pages.
- Breadcrumbs reflect real hierarchy.
- Pagination has crawlable links.
- Important filters do not create unbounded URL traps.
- Archive pages do not bury strategic content by date alone.
Schema should confirm the page role
Schema markup does not rescue a confused site. It confirms a clear one.
If a page is a canonical guide, schema should reinforce the article, organization, author, topic, and breadcrumbs where appropriate. If it is a product page, product and organization signals should align with the visible content. If it is documentation, the structure should make the technical purpose clear.
What fails is schema sprayed across templates without regard for page role. A blog post, comparison page, and product landing page should not all emit the same generic structured data just because the CMS makes it easy.
Use schema to answer these questions:
- What is this page?
- Who published it?
- What entity does it discuss?
- How does it relate to the rest of the site?
- Is there a clear primary topic?
llms.txt belongs in the routing layer
Emerging files like llms.txt are not magic ranking switches. They are routing and orientation tools. They can help AI systems understand what content you want surfaced, how your site is organized, and which resources matter.
If you use llms.txt, connect it to the same topology decisions you make elsewhere. Do not list random URLs. Point to canonical resources, documentation, high-quality explanations, and durable pages. If you need the operational basics, our explainer on llms.txt and skill.md covers what these files are for and what teams usually put in them.
A useful way to think about llms.txt is as a map at the edge of the site. It should agree with your internal links, sitemap, robots policy, and content strategy.
Metadata drift happens when titles, descriptions, canonicals, schema, headings, and internal links slowly stop agreeing with each other.
It is common after redesigns, CMS migrations, and content refreshes. A page gets repurposed, but its schema still reflects the old type. A canonical tag points to a weaker page. A hub links to an outdated guide. A product page claims ownership of a topic that the blog handles better.
For answer engines, drift creates ambiguity. Ambiguity increases the chance that another source gets cited instead.
Practical rule: Treat metadata drift as an architecture defect, not a copywriting cleanup task.
Measure topology optimization with operational signals
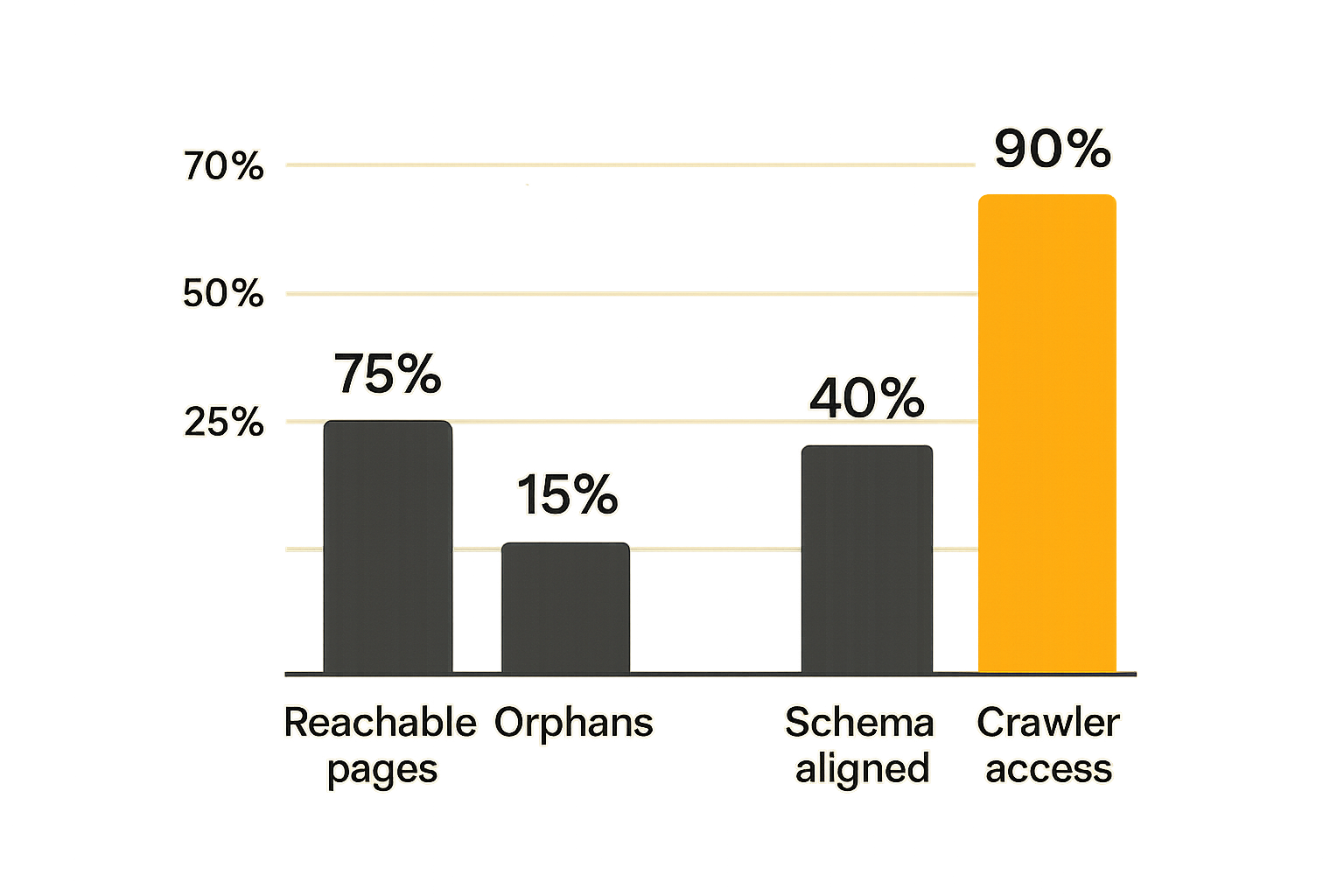
Discovery signals
Topology optimization needs measurement, but not fake precision. You cannot fully see how every answer engine selects sources. You can still measure whether your site is becoming easier to crawl and understand.
Start with discovery signals:
- Important pages reachable within a target click depth
- Number of orphan strategic pages
- Ratio of canonical answer pages with relevant inbound links
- Crawlable HTML links to key hubs
- Pages blocked by robots rules or AI-bot policies
- Pages missing from sitemaps or llms.txt when they should be included
These are operational metrics. They tell you whether your architecture matches your intent.
Citation readiness signals
Citation readiness is not the same as citation guarantee. It means the page has the properties a system would reasonably need to use it as a source.
Look for:
- Clear answer in the first meaningful section
- Visible author or organization signal
- Updated date where freshness matters
- Supporting internal links
- Consistent schema and metadata
- Specific claims backed by examples, documentation, or evidence
- No conflicting canonical or noindex directives
For adjacent reading, teams handling sensitive communication systems face a similar difference between having a feature and having an operational workflow; related reading from our network: VA secure messaging workflow architecture.
Change control metrics
Topology optimization is not a one-time cleanup. Every content launch, redesign, and CMS change can improve or damage the graph.
Track changes like an operator:
- Which pages gained or lost inbound links?
- Which canonical pages changed status?
- Which templates changed schema output?
- Did the navigation change remove crawler-visible routes?
- Did a new content cluster create duplicates?
If your team already uses pull requests or release tickets, add topology checks. If your team works mostly in a CMS, add a publishing checklist. Either way, do not rely on memory.
What breaks when topology optimization is done badly
Thin hubs and doorway pages
A hub page should help machines and humans understand a topic area. It should not be a thin list of links wrapped in generic copy.
Thin hubs fail because they add another node without adding context. They may even make the graph worse by placing a weak intermediary between crawlers and strong pages.
What works:
- Hubs with a clear topic statement
- Short descriptions explaining each linked resource
- Links grouped by intent or workflow stage
- A stable relationship to canonical answer pages
What fails:
- Auto-generated tag pages
- Date archives pretending to be topic hubs
- “Resources” pages with no hierarchy
- Hubs that target the same answer as the canonical guide
Conflicting canonicals
Canonicals are topology instructions. They tell crawlers which URL should represent a piece of content.
When canonicals conflict with internal links, sitemaps, hreflang, or visible navigation, you create unnecessary uncertainty. A common pattern: the navigation links to Page A, the canonical points to Page B, the sitemap includes both, and the blog keeps linking to an older Page C.
In traditional SEO, this can dilute signals. In AEO, it can also confuse source selection. If your own site cannot decide which page owns the answer, do not expect an answer engine to make the decision you wanted.
JavaScript-only routes and blocked bots
Some AI crawlers can render JavaScript. Some cannot. Some may render partially. Some may obey different bot policies. The safest operational assumption is that critical content and critical routes need resilient access.
Common failure modes:
- Main content injected only after delayed client-side calls
- Important links generated after user interaction
- Bot rules that accidentally block AI crawlers from strategic pages
- CDN or WAF settings that challenge non-browser agents
- Schema emitted inconsistently between server and client
This does not mean every site needs to be static HTML. It means your important AEO paths should not depend on a fragile execution chain.
Implementation workflow for website teams
Step 1: decide owned questions
Topology optimization starts with business judgment. You cannot optimize every possible question equally.
Create a list of questions your site should own in AI answers. Prioritize questions that connect to your product, expertise, category, or defensible point of view.
Then classify each question:
- Must-own: core to your positioning and revenue.
- Should-own: important to education and comparison.
- Support-only: useful as evidence, but not a primary citation target.
- Ignore for now: not worth architectural effort.
This prevents the content team from treating every keyword as equal. It also gives developers and marketers a shared map.
Step 2: assign page roles
For each must-own and should-own question, assign page roles before writing or editing.
Use a simple sequence:
- Pick the canonical answer URL.
- Identify supporting proof pages.
- Choose or create a hub route.
- Define internal links from support pages to the canonical page.
- Align schema, title, description, canonical tag, and breadcrumbs.
- Add the page to sitemap and llms.txt if appropriate.
- Validate crawler access.
The numbered workflow matters because it keeps teams from optimizing fragments. Developers know what templates need changes. SEO teams know which links matter. Content strategists know which pages should not compete.
Related reading from our network: marketplace operators face a similar prioritization problem when comparing platform choices, as shown in this practical strategy piece on Upwork alternatives for freelancers; different niche, same need to map trust, workflow, and discovery.
Step 3: ship and validate in batches
Do not rebuild your entire site graph in one release unless you have to. Ship in batches by topic cluster.
A workable release plan:
- Week 1: audit one topic cluster and identify canonical pages.
- Week 2: fix internal links, breadcrumbs, and hub copy.
- Week 3: align schema and metadata.
- Week 4: validate crawler access and monitor changes.
- Week 5: repeat for the next cluster.
This is slower than a one-week content sprint, but it is easier to debug. If citations, crawl behavior, or visibility improve, you know which cluster changed. If something breaks, you can isolate the cause.
Where CrawlProof fits in the topology optimization workflow
See what AI crawlers can actually reach
The theory is useful. The audit is where reality shows up.
CrawlProof is built for site owners and marketers who need to see their pages the way AI crawlers and answer engines see them. It checks what content, schema, robots rules, AI-bot access, and positioning are actually visible from a crawler-oriented perspective.
That matters because topology optimization fails when teams operate from assumptions. The CMS preview looks fine. The browser looks fine. The sitemap looks fine. Then the audit shows that the canonical answer page is buried, the schema is inconsistent, or a crawler policy blocks the route you care about.
You can run an AEO audit from CrawlProof’s site scanner and use the findings as a starting point for topology decisions rather than guessing from the visual page alone.
Turn findings into an AEO backlog
A good topology optimization backlog should not be a vague list of “AI improvements.” It should contain concrete architecture and workflow fixes:
- Add crawler-visible links from hub pages to canonical answers.
- Move a strong orphan article into a topic cluster.
- Update schema to match page role.
- Fix conflicting canonical tags.
- Add or clean up llms.txt entries.
- Unblock appropriate AI crawlers where policy allows.
- Rewrite anchors that fail to describe the destination.
- Reduce duplicate pages competing for the same answer.
If you want to see how the team thinks about these problems over time, the CrawlProof blog covers AEO, LLM crawlers, schema markup, llms.txt, and the practical mechanics of getting cited by answer engines.
The practical question is not whether topology optimization is a new buzzword. It is whether your site graph helps or hurts AI systems trying to understand your expertise. In 2026, that is becoming part of the job for website owners, SEO professionals, content strategists, and developers.
Topology optimization closes the gap between having good content and making that content discoverable, connected, and citation-ready.
Try crawlproof.com
CrawlProof helps site owners and marketers understand how AI answer engines and LLM crawlers discover and cite their content. Try crawlproof.com to see your site the way AI crawlers do and turn topology optimization into a practical AEO backlog.
